

사전 준비
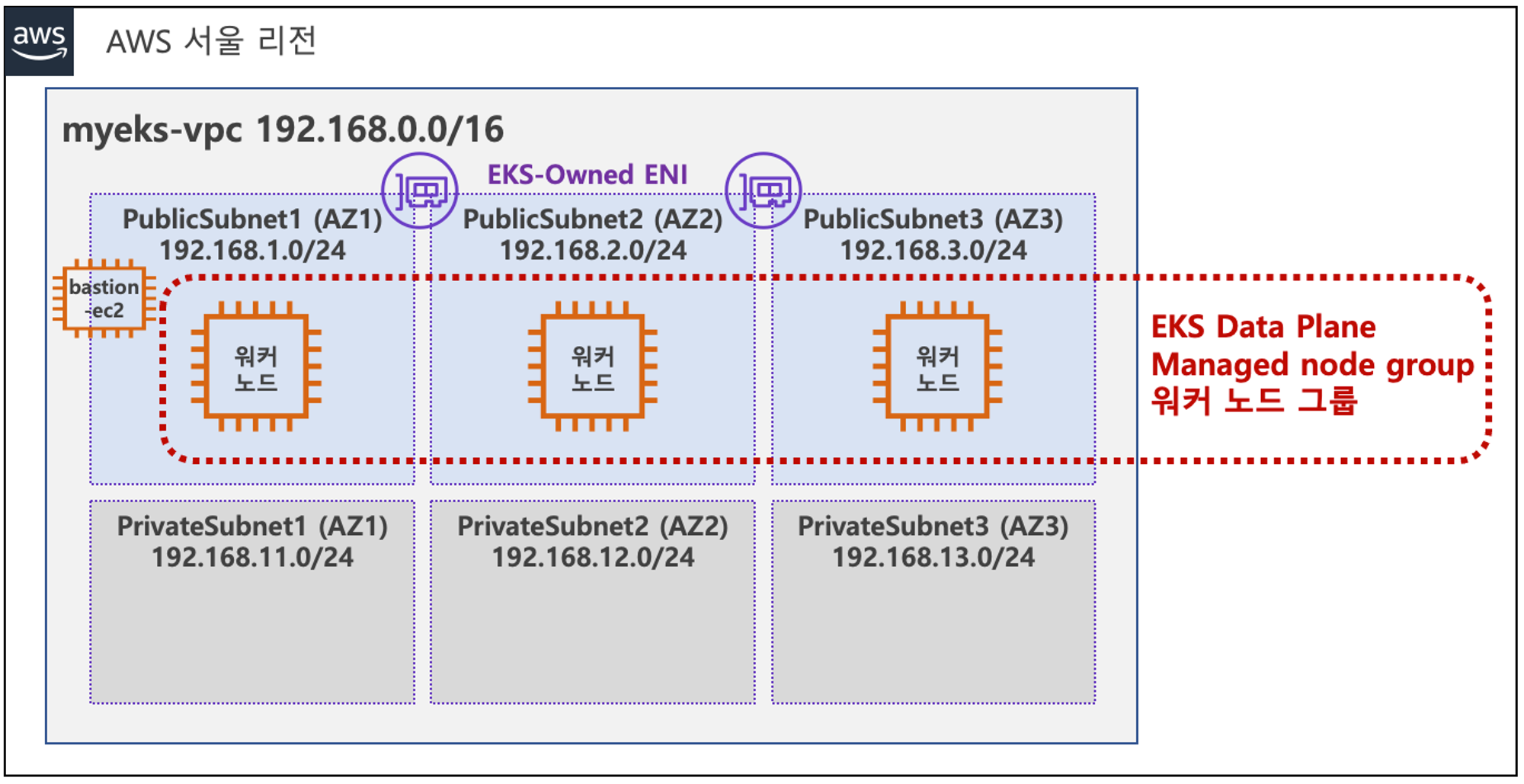
위와 같이 사전 준비가 필요합니다. 저번 글에서 설명했듯이, EKS를 배포하기 위한 VPC를 생성하고, Public Subnet, Private Subnet을 생성합니다. 그 후 EKS Cluster에 접근하기 위한 bastion EC2를 미리 생성합니다.
추가로 지난번 실습 때 진행했었던 ExternalDNS와 AWS LB Controller, EBS csi driver 설치, gp3 스토리지 클래스 생성까지 해주시고, Prometheus와 Grafana까지 설치합니다.
Cluster AutoScaler(CA)
Cluster Autoscaler(CA)는 EKS cluster에서 Worker Node의 리소스가 부족하거나 과도하게 할당되었을 때 자동으로 Node를 추가하거나 제거하여 Node의 가용성을 유지합니다.
CA의 제약 조건
CA를 사용할 때에는 아래와 같이 몇가지 제안된 규칙이 있습니다.
- 오토스케일링 전략은 EC2의 오토스케일링 그룹 사용을 중심으로 합니다.
- 노드 그룹에서 인스턴스 타입이 동일하다고 가정합니다.
- 혼합 인스턴스 타입은 가능한 CPU와 메모리가 균등하여야 합니다.
- 다양한 인스턴스 타입을 지원하기 위해서는 여러 노드 그룹이 필요합니다.
- 모범사례는 AZ당 노드 그룹을 가지는 것입니다.
CA Architecture
AWS EKS에서는 Auto Scaling Group(ASG)를 사용하여 CA를 적용합니다.
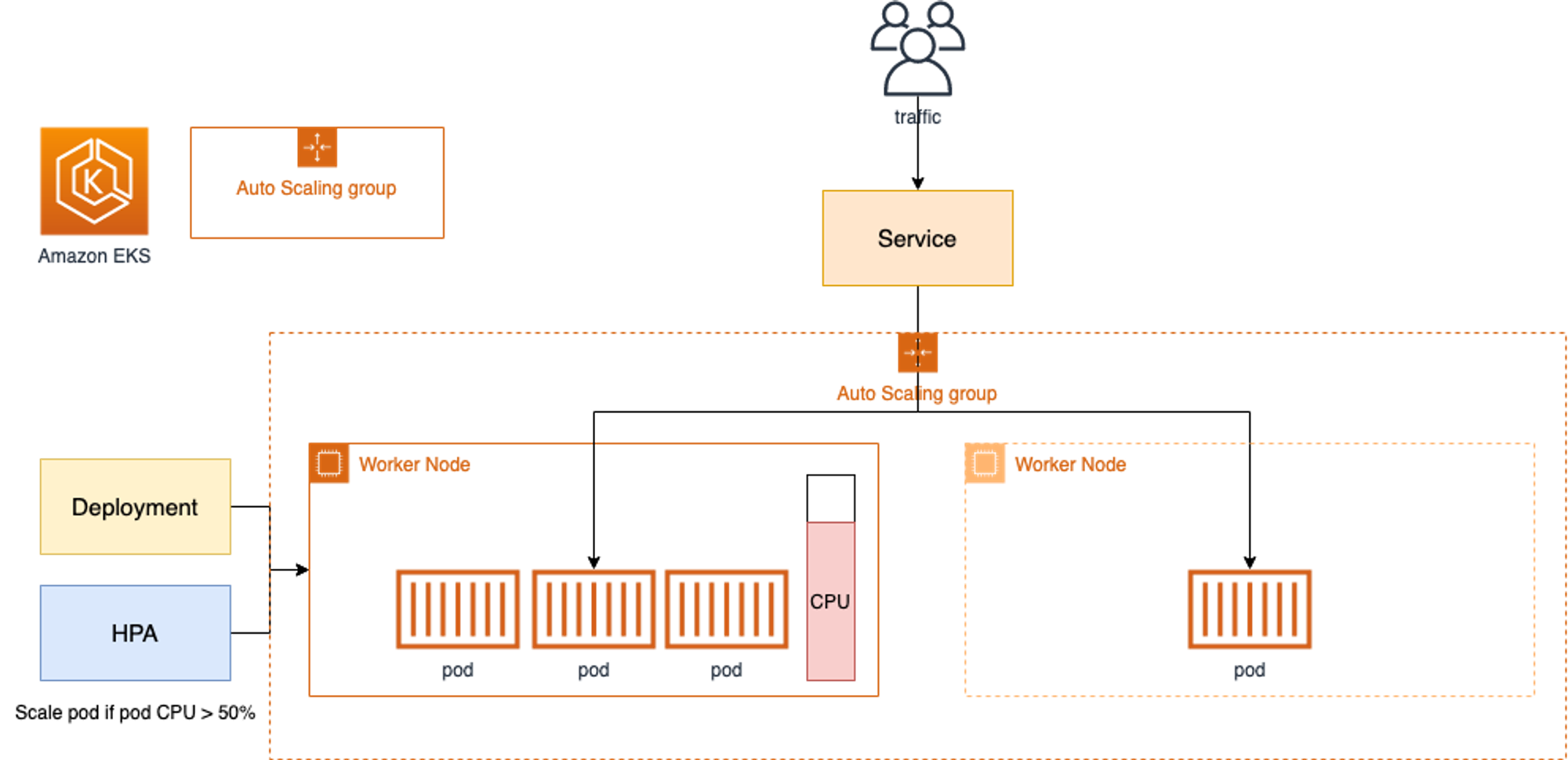
Cluster Autoscale를 동작 하기 위해서는 cluster-autoscaler 파드(디플로이먼트)를 배치합니다. 그 후 CA는 pending 된 pod가 존재할 경우 worker node를 scale-out하며 특정 시간을 간격으로 사용률을 확인하여 scale-in/out을 진행합니다.
CA 설정
aws ec2 describe-instances --filters Name=tag:Name,Values=$CLUSTER_NAME-ng1-Node --query "Reservations[*].Instances[*].Tags[*]" --output yaml | yh
위의 명령어를 통해 tag를 확인해보겠습니다.
...
- Key: k8s.io/cluster-autoscaler/myeks
Value: owned
- Key: k8s.io/cluster-autoscaler/enabled
Value: 'true'
...
cluster-autoscaler/enabled key값의 true로 설정되어있습니다.
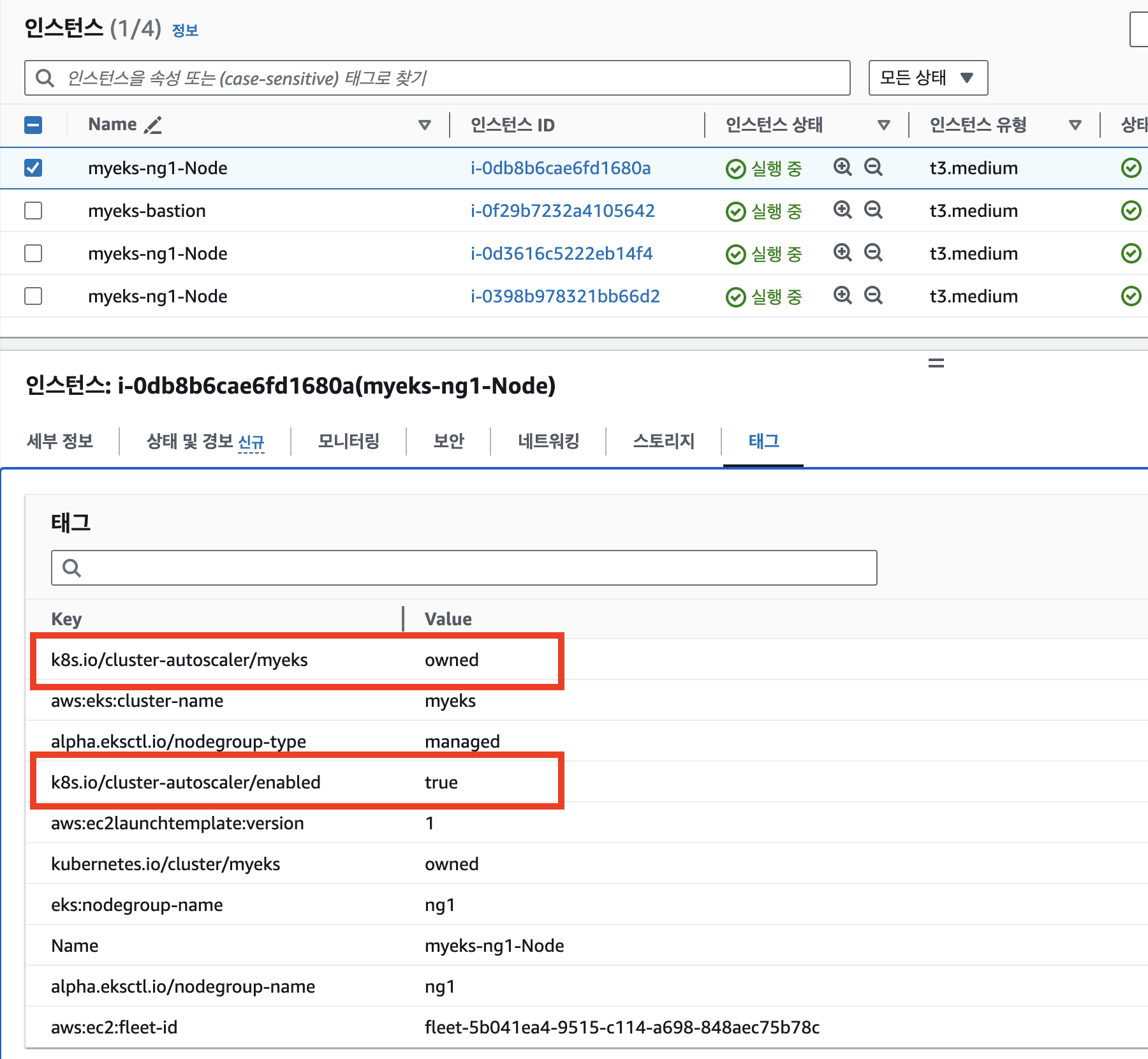
또한 AWS Managed Console에서 EC2 메뉴에 접근하신 후 Worker Node Instance의 tag에서도 같은 값을 확인하실 수 있습니다.
CA 실습
ASG MaxSize 설정
CA를 배포하기에 앞서 현재 autoscaling(ASG)의 MaxSize를 늘려주셔야 합니다.
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='myeks']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
위의 명령어를 통해 현재 ASG의 MinSize, MaxSize, DesiredCapacity를 확인하실 수 있는데, MinSize와 MaxSize가 같은 것을 보실 수 있습니다.
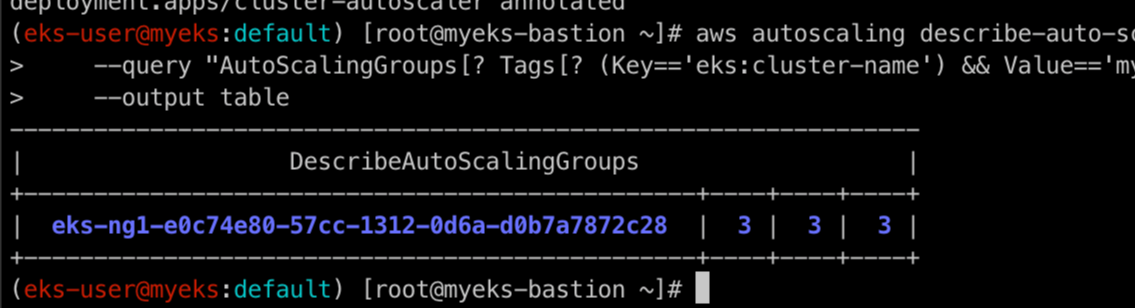
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 3 --desired-capacity 3 --max-size 6
위의 명령어를 통해 MinSize를 3으로 MazSize는 6으로 DesiredCapacity은 3으로 변경합니다.
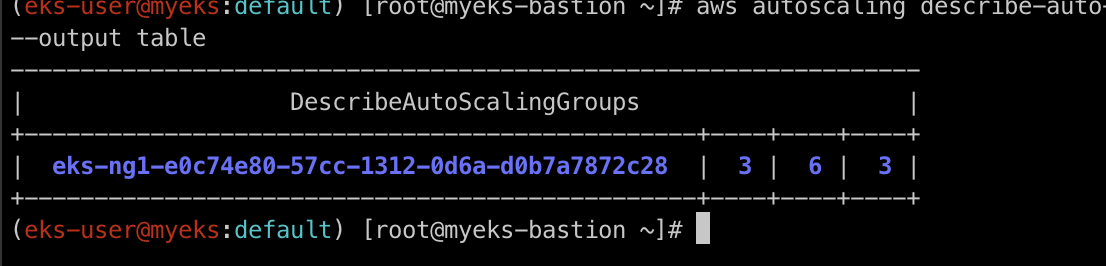
MaxSize가 6개로 변경된 것을 확인하실 수 있습니다.
CA 배포
curl -s -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
sed -i "s/<YOUR CLUSTER NAME>/$CLUSTER_NAME/g" cluster-autoscaler-autodiscover.yaml
kubectl apply -f cluster-autoscaler-autodiscover.yaml
위의 명령어를 통해 현재 Cluster에 CA를 배포합니다.
kubectl get pod -n kube-system | grep cluster-autoscaler
cluster-autoscaler Pod가 잘 생성되었는지 확인합니다.
kubectl -n kube-system annotate deployment.apps/cluster-autoscaler cluster-autoscaler.kubernetes.io/safe-to-evict="false"
그 후 위의 명령어를 통해 cluster-autoscaler의 deployment에 cluster-autoscaler.kubernetes.io/safe-to-evict가 false라는 annotation을 주어 cluster-autoscaler 파드가 동작하는 Worker Node는 퇴출(evict) 되지 않게 설정합니다.
즉, Cluster가 스케일 다운(scale down) 과정에서 리소스를 절약하기 위해 Pod를 재배치하거나 삭제할 때, 이 Deployment의 Pod는 삭제하거나 재배치하지 않도록 설정하는 것입니다.
CA 부하 테스트
부하테스트용 Pod 생성
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-to-scaleout
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
service: nginx
app: nginx
spec:
containers:
- image: nginx
name: nginx-to-scaleout
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
위의 Pod를 띄운 후 아래의 명령어로 pod의 수를 임의로 scale-out 하도록 하겠습니다.
kubectl scale --replicas=15 deployment/nginx-to-scaleout && date
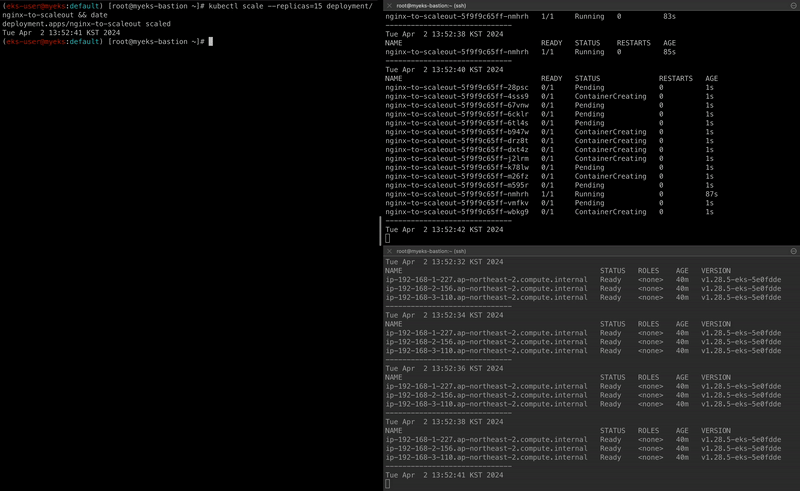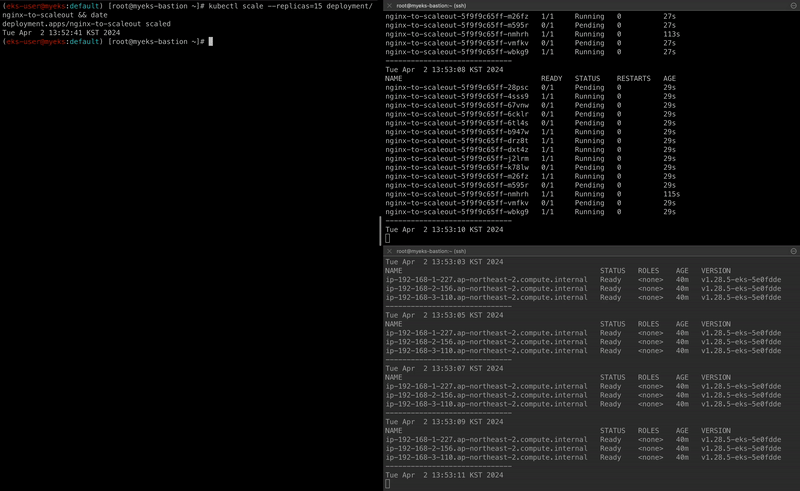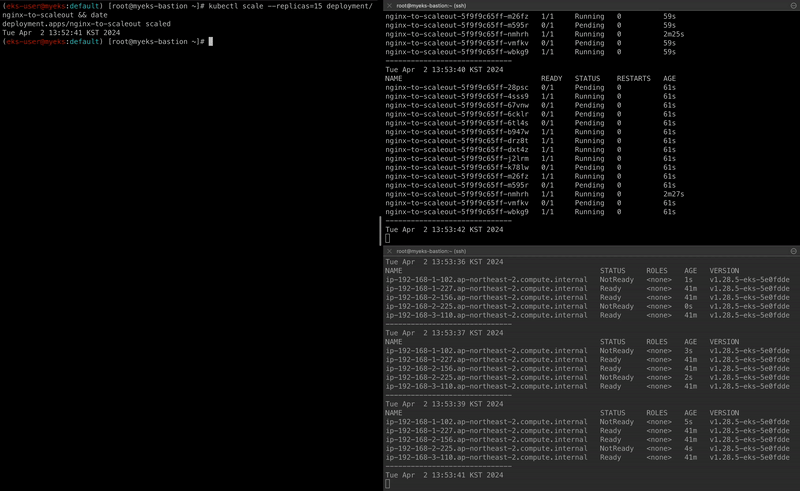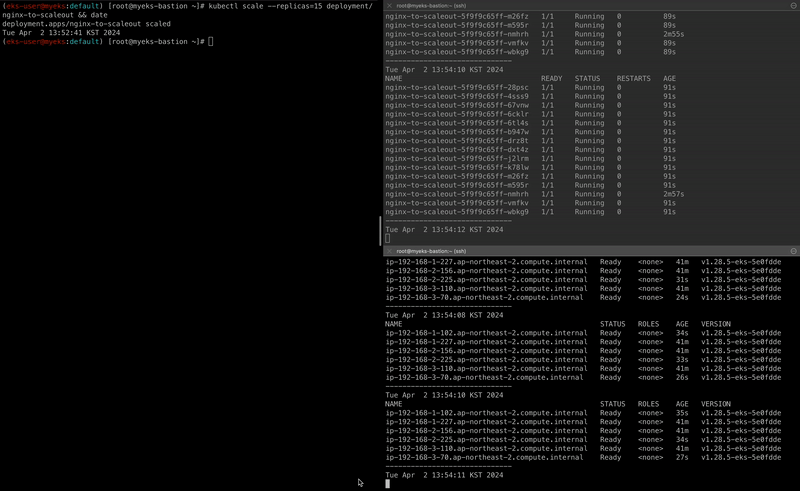
자세히 살펴보자면 scale-out을 통해 Pod의 replicas를 15개로 늘리면서 node의 리소스 요청량이 많아졌고, ASG를 통해 Worker Node의 수를 늘려 해당 Pod가 모두 배포됩니다.
CA의 문제점
위의 실습을 통해 CA의 기본 동작을 처리해보았습니다. 하지만 생성 요청된 Pod가 Node의 수가 부족하여 생성되지 않고 Node가 띄어질 때까지 Pending 상태로 머무는 것을 확인하셨을텐데요. 만약 이게 실제 서버 운영중이라면 너무 치명적인 단점이 될 것 입니다.
이처럼 CA의 문제점은 여러가지가 있습니다.
- ASG에만 의존하고 직접 Node 생성 / 삭제등에는 관여하지 않습니다.
- EKS에서 Node를 삭제해도 정작 EC2에서 Instance는 삭제되지 않습니다.
- Node가 축소될 때 Pod가 적은 Node나 Draint 된 Node부터 축소가 되기에 특정하기 매우 어렵습니다.
- 특정 Node를 삭제하면서 동시에 Node의 개수를 줄이기 어렵습니다. (즉, 삭제 옵션이 다양하지 않습니다.)
- polling 방식이기에 자주 실행하면 API 제한에 도달할 수 있습니다.
- Scaling 속도가 매우 느립니다.
즉, CA는 Kubernetes Cluster 자체의 AutoScaling을 의미하며 수요에 따라 Worker Node를 추가하는 기능인데, 각 Worker Ndoe의 부파 평균이 높아졌을 때 추가되는 것으로 보입니다. 하지만 실제로는 Scale-out한 Pod가 처음 생성되어 Pending 상태가 되었을 때 CA가 동작합니다. (즉, Node의 리소스가 부족한 상황에 동작하지 않습니다!)
위의 문제점에 의해서 중간에 ASG없이 Kubernetes가 직접 EC2를 관리할 수 있게 나온 기술이 바로 Karpenter 입니다.
CPA
Karpenter를 보기전에 CPA를 먼저 보도록 하겠습니다.
CPA(Cluster Proportional Autoscaler)는 Cluster 내의 Node수나 총 CPU, Mem 자원등의 크기에 따라 애플리케이션(컨테이너/파드)를 Scaling하는 도구입니다.
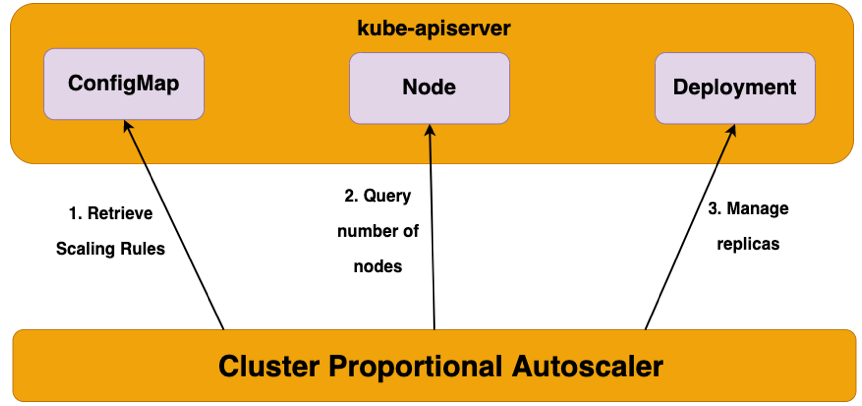
CPA 실습
CPA 설치
helm repo add cluster-proportional-autoscaler https://kubernetes-sigs.github.io/cluster-proportional-autoscaler
Pod 배포
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
cpu: "100m"
memory: "64Mi"
requests:
cpu: "100m"
memory: "64Mi"
ports:
- containerPort: 80
CPA 정책 배포
config:
ladder:
nodesToReplicas:
- [1, 1]
- [2, 2]
- [3, 3]
- [4, 3]
- [5, 5]
options:
namespace: default
target: "deployment/nginx-deployment"
가장 중요한 CPA 정책 배포입니다.
중요한 부분은 config.ladder.nodeToReplicas인데, [] 배열에서 앞부분이 node의 개수, 뒷부분이 Replica의 개수입니다.
options를 통해 어떤 namespcae에 있는 target를 설정할 것인지 명시해줍니다.
"coresToReplicas":
[
[ 1, 1 ],
[ 64, 3 ],
[ 512, 5 ],
[ 1024, 7 ],
[ 2048, 10 ],
[ 4096, 15 ]
],
이런식으로 CPU/Memory 기반의 정책도 설정 가능합니다.
helm upgrade --install cluster-proportional-autoscaler -f cpa-values.yaml cluster-proportional-autoscaler/cluster-proportional-autoscaler
그 후 해당 정책을 CPA에 적용시킵니다.
노드 5개로 증가


현재 Node의 수가 는 3개이고, Pod의 수도 3개인 것을 확인하실 수 있습니다.
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 5 --desired-capacity 5 --max-size 5
위의 명령어로 Node의 수를 5개로 늘리도록 하겠습니다.


그러면 위에서 설정한 CPA 정책에 맞게 Node의 수가 5개이기에 Pod가 5개 띄어진 것을 확인하실 수 있습니다.
노드 4개로 축소
aws autoscaling update-auto-scaling-group --auto-scaling-group-name ${ASG_NAME} --min-size 4 --desired-capacity 4 --max-size 4
그렇다면 Node를 4개로 축소해보도록 하겠습니다.


설정한 CPA 정책에 맞게 Node의 수가 4개가 되었으니 5개였던 Pod의 수가 3개로 감소되었습니다!
'스터디 이야기 > AWS EKS' 카테고리의 다른 글
| [AEWS] 6-1. Amazon EKS - Security (EKS 인증/인가) (0) | 2024.04.09 |
|---|---|
| [AEWS] 5-3. Amazon EKS - AutoScaling (Karpenter) (0) | 2024.04.02 |
| [AEWS] 5-1. Amazon EKS - Autoscaling (HPA, KEDA, VPA) (0) | 2024.04.01 |
| [AEWS] 4-3. Amazon EKS - Observability (Grafana) (1) | 2024.03.29 |



