

사전 준비
위와 같이 사전 준비가 필요합니다.
저번 글에서 설명했듯이, EKS를 배포하기 위한 VPC를 생성하고, Public Subnet, Private Subnet을 생성합니다. 그 후 EKS Cluster에 접근하기 위한 bastion EC2를 미리 생성합니다.
추가로, 지난번 실습 때 진행했었던 ExternalDNS와 AWS LB Controller, EBS csi driver 설치, gp3 스토리지 클래스 생성까지 해주셔야합니다.
4-2. Amazon EKS - Observability (Prometheus) 에서 이어집니다.
Grafana
Grafana란?
Grafana란 시계열 매트릭 데이터를 시각화하여 최적화된 대시보드를 제공해주는 오픈소스이며, Prometheus를 통해 수집된 TSDB 데이터를 시각화하고, 다양한 데이터 형식을 지원합니다.
이전 포스팅에서 Grafana를 포함하여 kube-prometheus-stack을 설치하였기 때문에 그대로 실습을 진행해보겠습니다.
Grafana 실습
Ingress 확인
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
해당 명령어로 반환된 HOSTS를 통해 Grafana에 접근하도록 하겠습니다. (기본적으로 계정 정보는 admin / prom-operator입니다!)
Grafana 접근
메뉴 설명
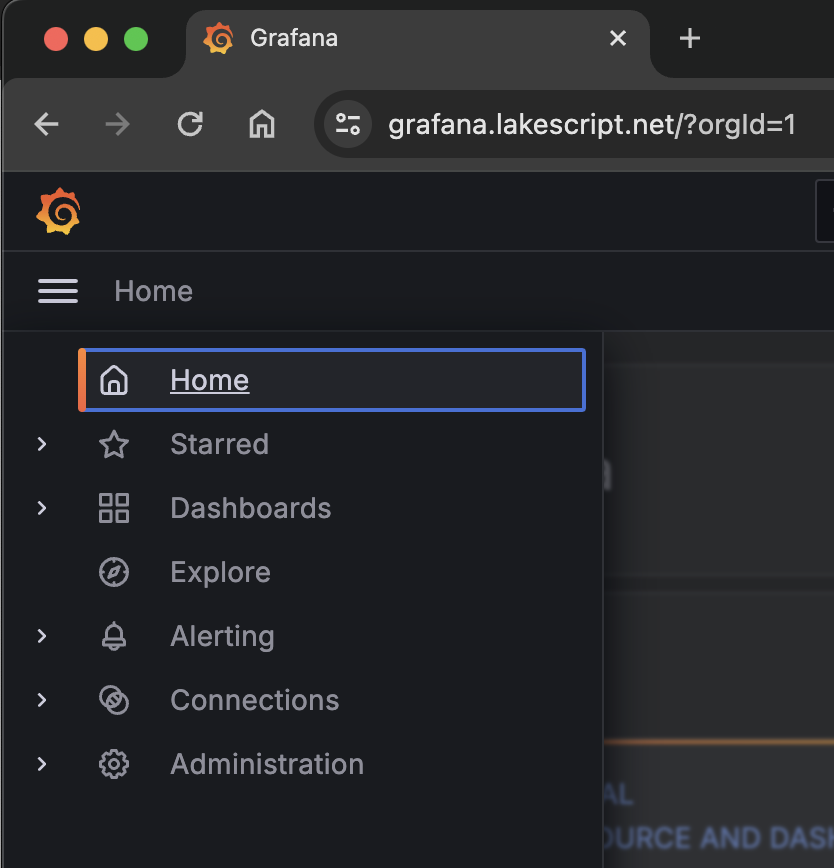
- Search dashboards : 대시보드 검색
- Starred : 즐겨찾기 대시보드
- Dashboards : 대시보드 전체 목록 확인
- Explore : 쿼리 언어 PromQL를 이용해 메트릭 정보를 그래프 형태로 탐색
- Alerting : 경고, 에러 발생 시 사용자에게 경고를 전달
- Connections : 설정, 예) 데이터 소스 설정 등
- Administartor : 사용자, 조직, 플러그인 등 설정
Connections 설정
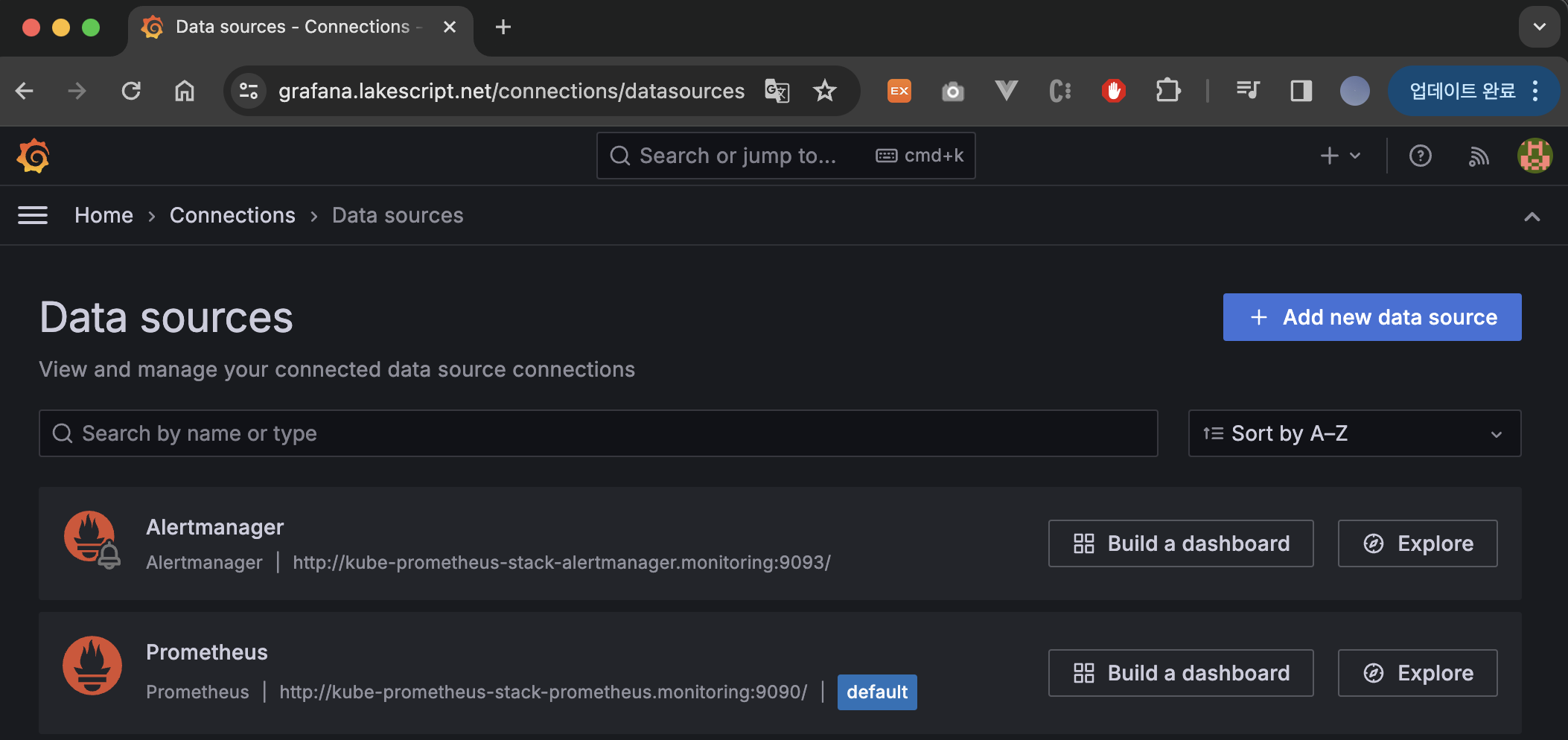
Grafana를 사용하려면 기본적으로 DataSource가 연동되어 있어야 합니다.
이전에 kube-prometheus-stack을 통해 설치하였기 때문에 기본적으로 Alertmanger와 Prometheus는 연동되어 있습니다.
Data Source 실습
새로운 pod를 하나 만들어 실제로 Data source에 접속이 되는지 확인해보겠습니다.
netshoot-pod 생성
apiVersion: v1kind: Podmetadata: name: netshoot-podspec: containers: - name: netshoot-pod image: nicolaka/netshoot command: ["tail"] args: ["-f", "/dev/null"] terminationGracePeriodSeconds: 0
접속 확인
kubectl exec -it netshoot-pod -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v ; echo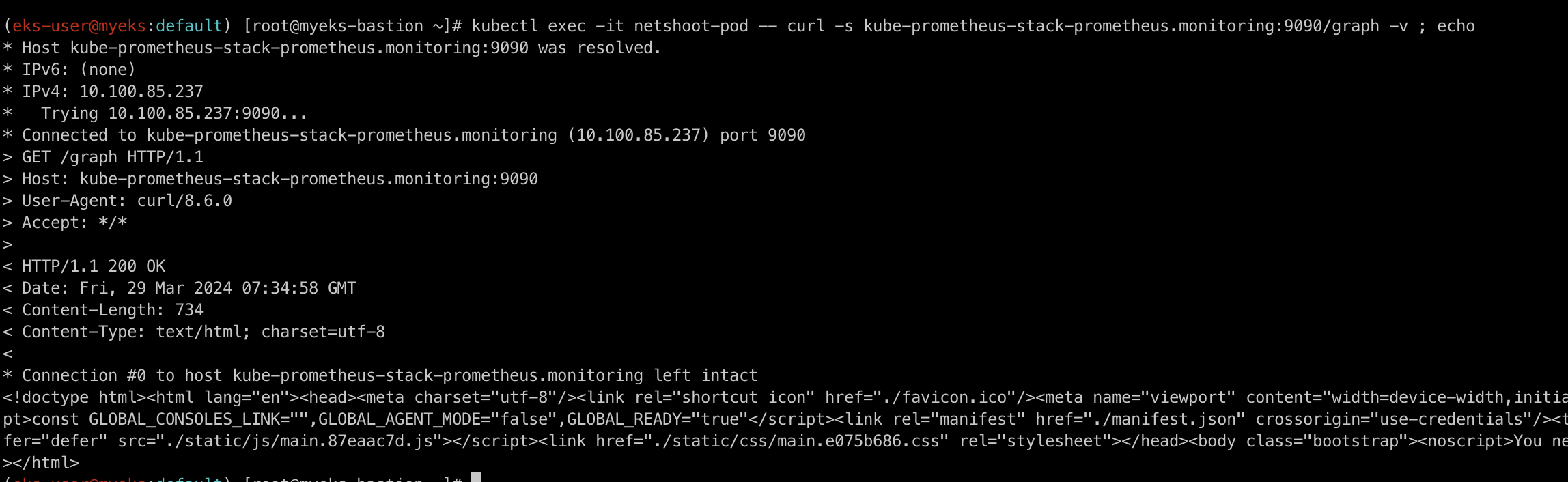
위의 명령어를 통하여 netshoot-pod에서 kube-prometheus-stack-prometheus.monitoring:9090/graph 으로 접근이 정상적으로 되는 것을 확인하실 수 있습니다.
Grafana DashBoard
이제 가장 중요한 DashBoard에 대해 살펴보겠습니다.
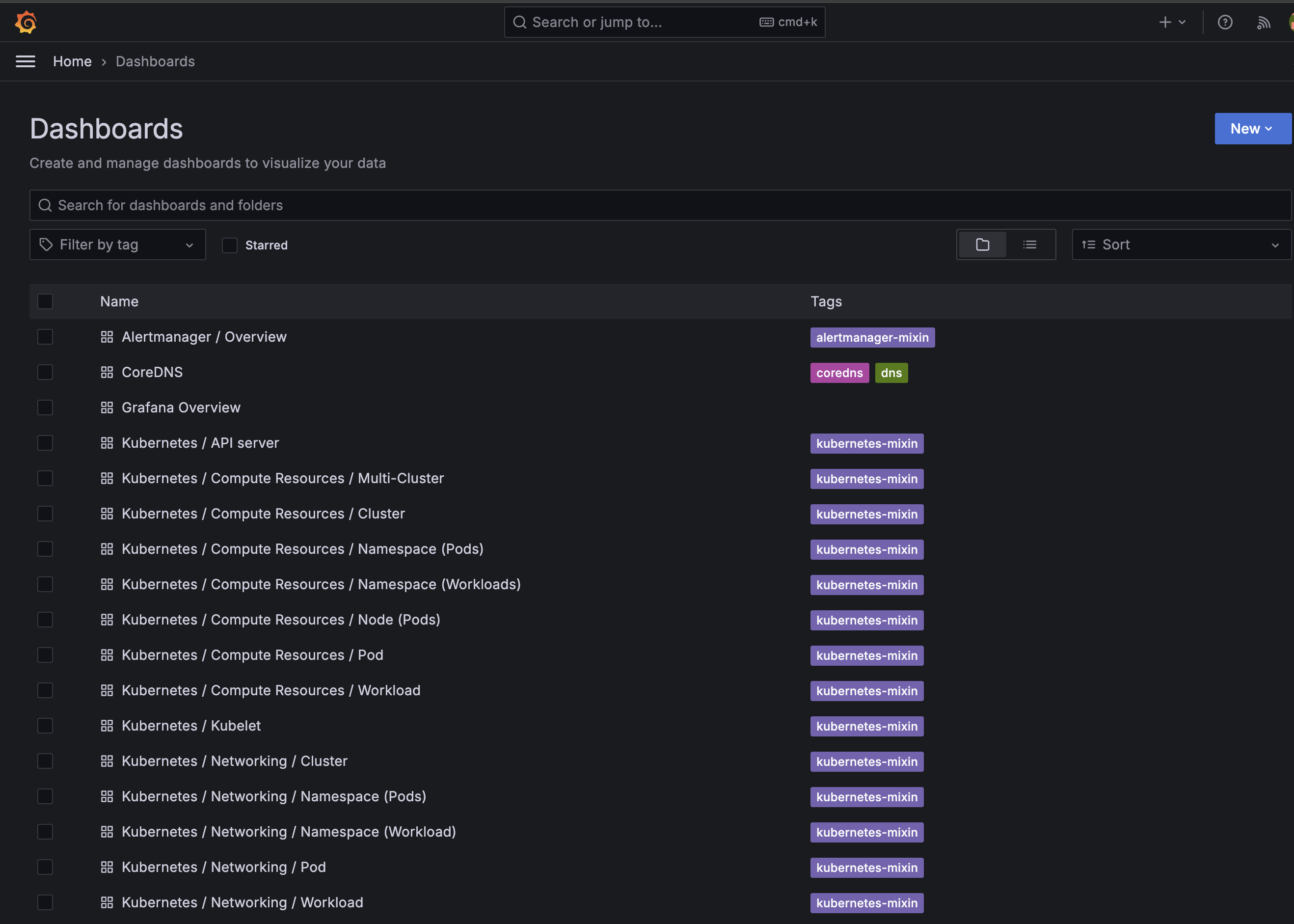
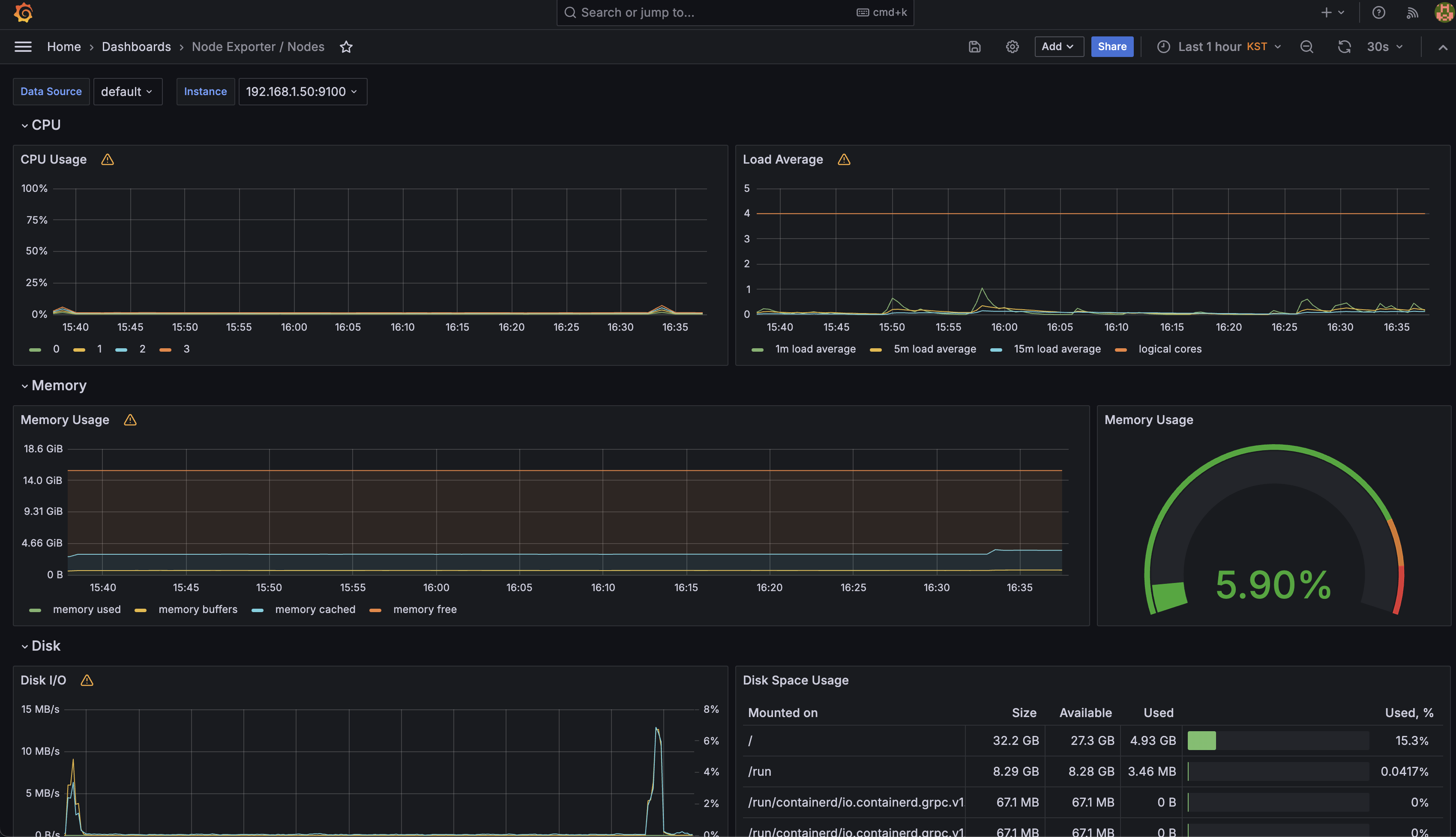
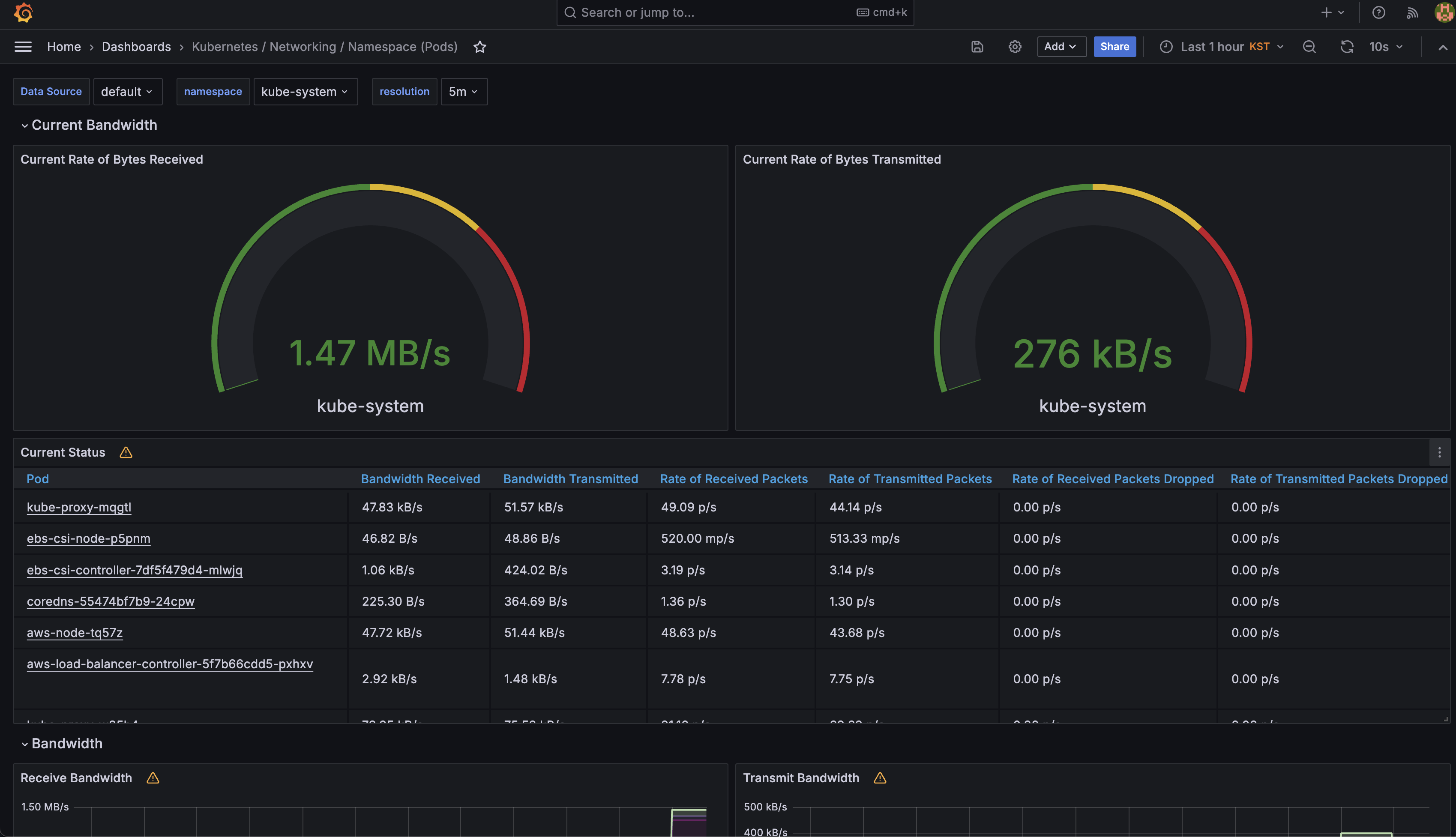
위의 이미지처럼 기본적으로 Grafana에서 제공되는 DashBoard도 상당히 뛰어납니다.
하지만 상당히 생태계가 잘 형성된 오픈소스이다보니 다른 사람들이 만든 DashBoard도 import하여 사용하실 수 있습니다.
공식사이트에서 확인가능하며, 몇개의 추천 DashBoard를 사용해보겠습니다.
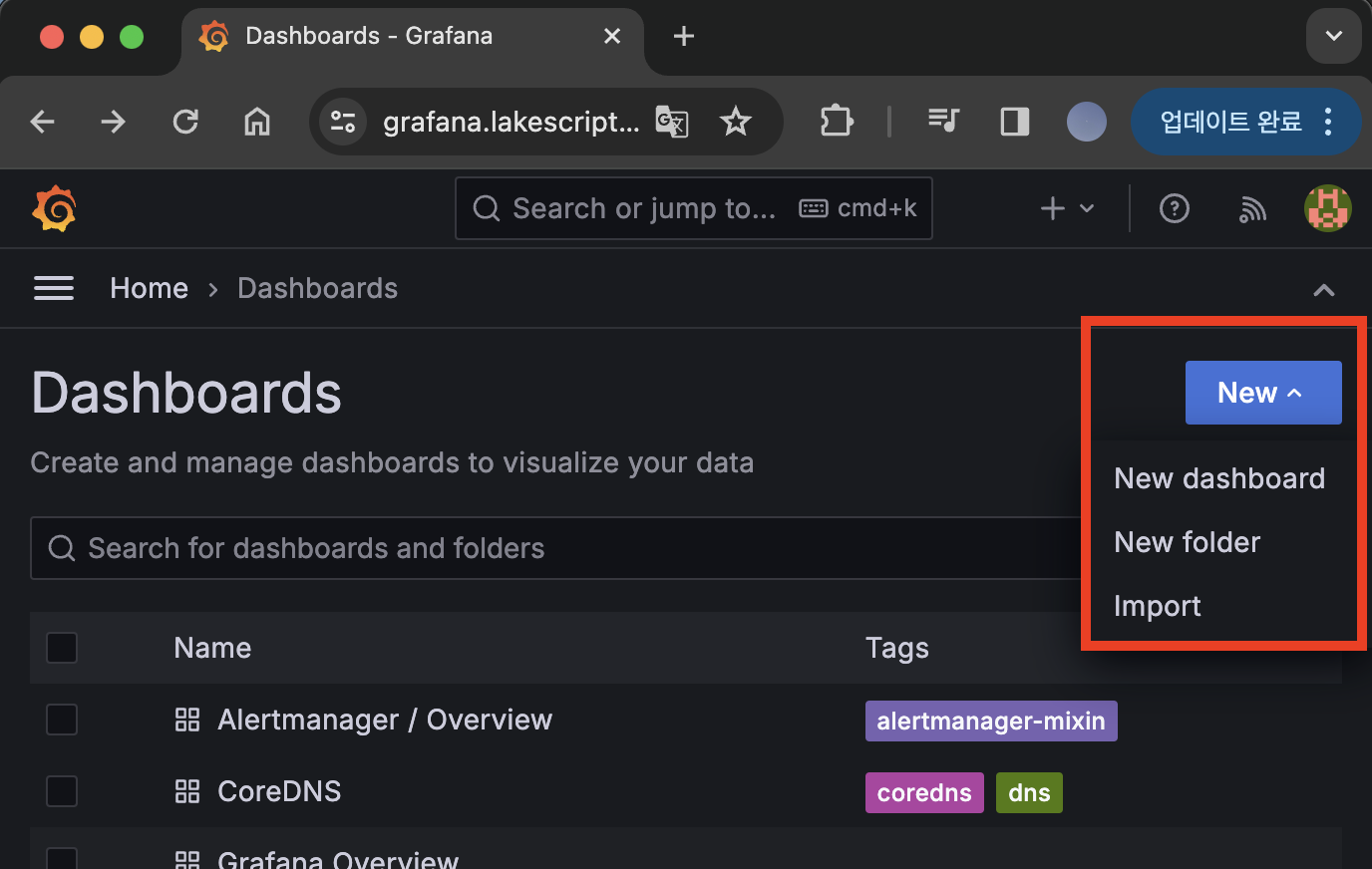
Dashboard 화면에서 New > Import에 접근합니다.
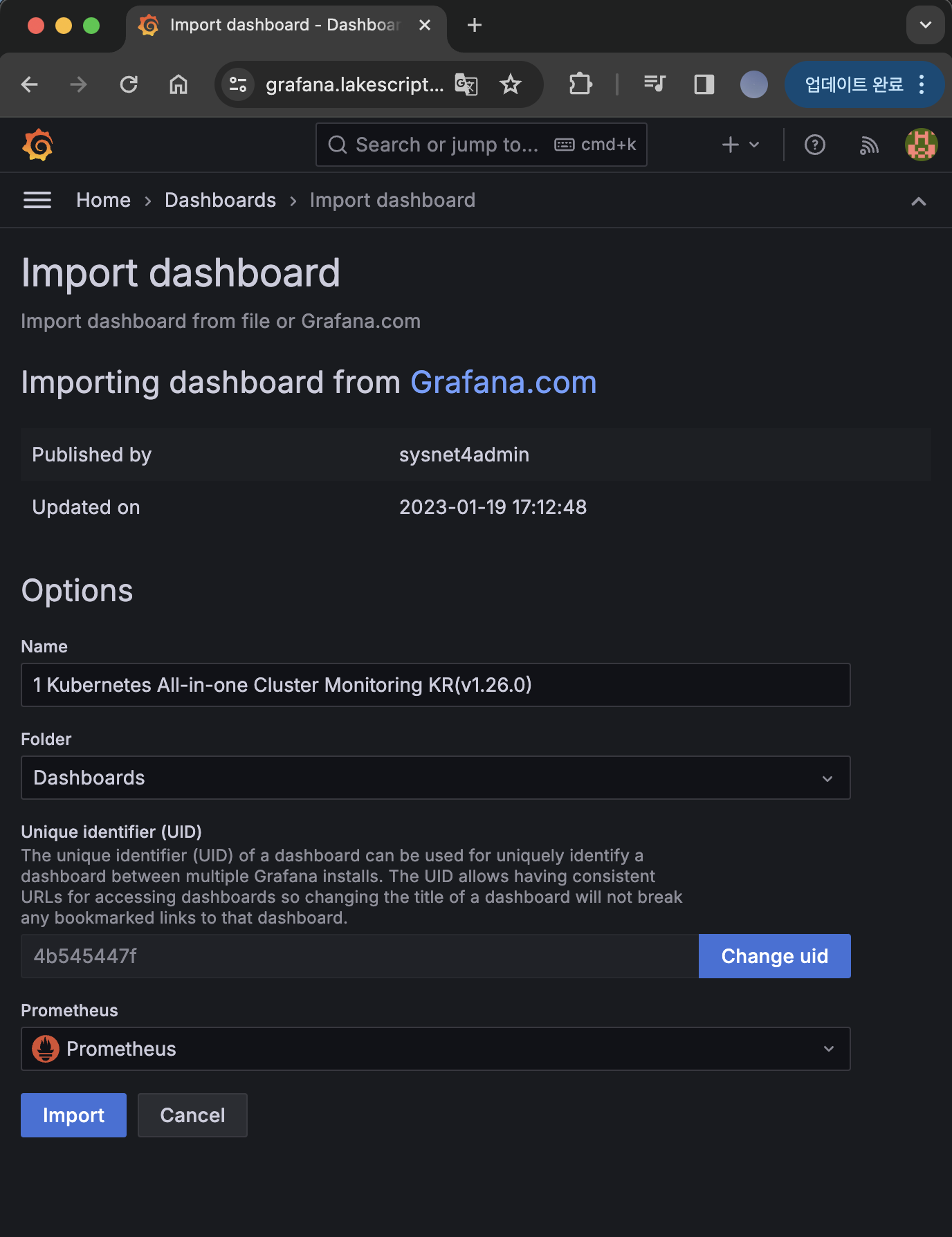
그 후 17900 번호를 입력한 후 Import 해줍니다.
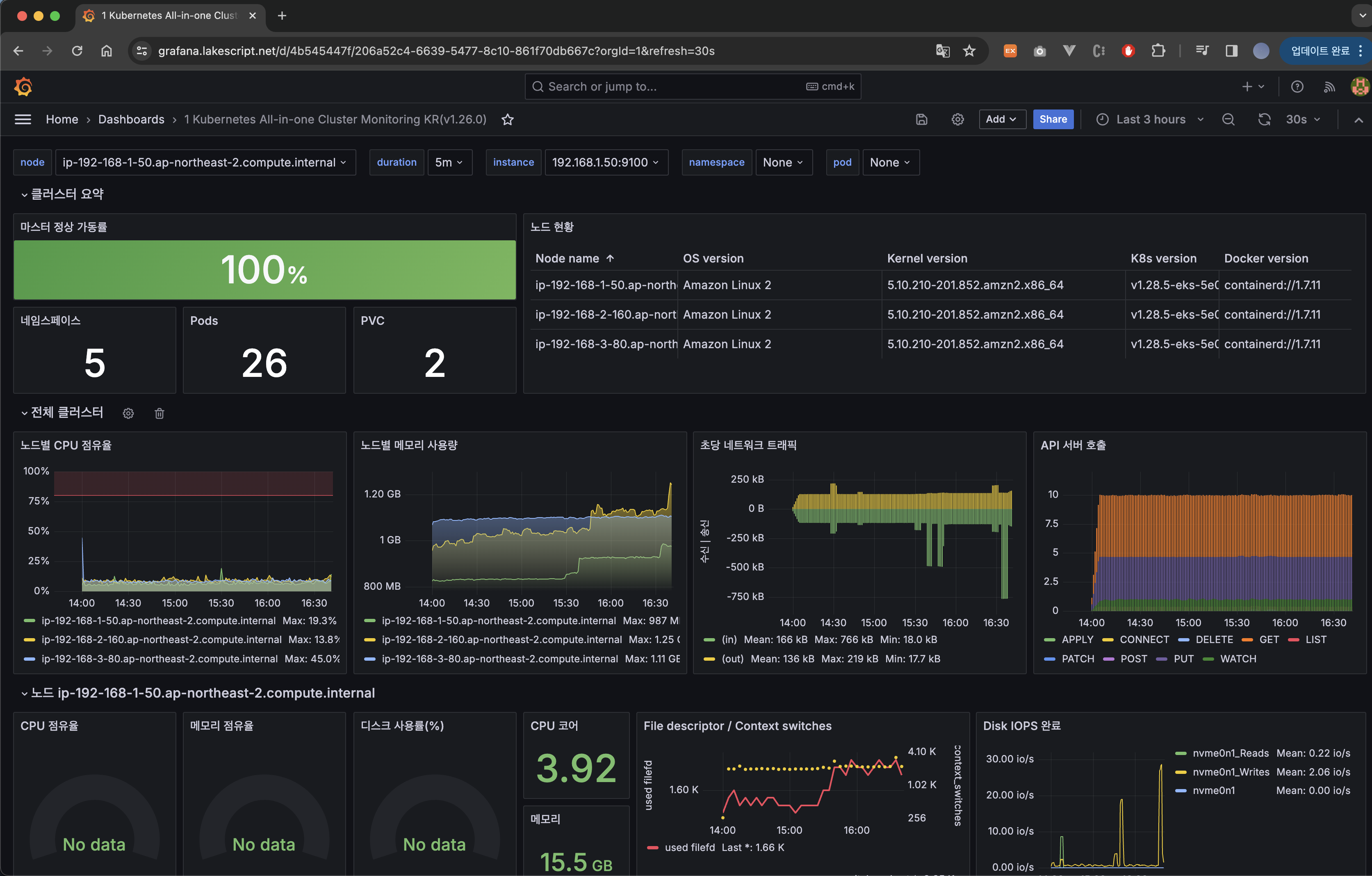
그럼 위와 같이 Dashboard가 Import 되었습니다.
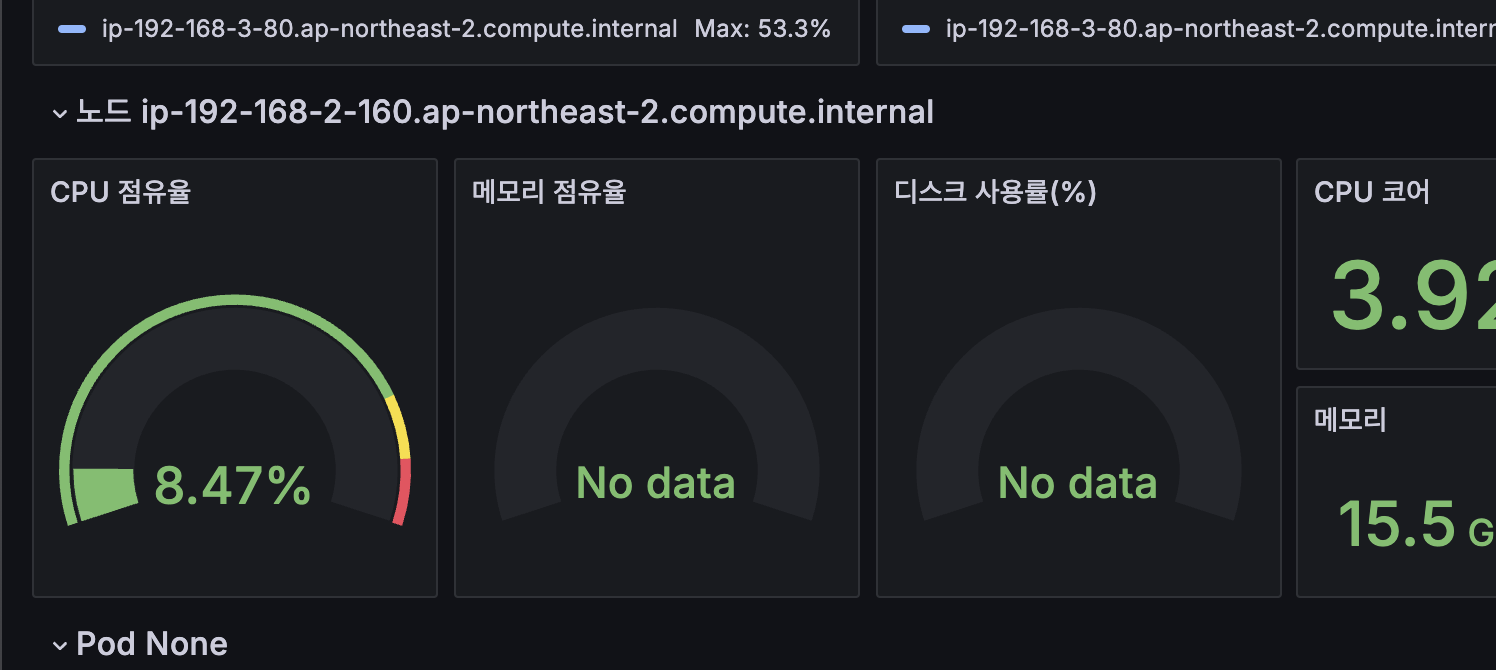
근데 저중 CPU 점유율, 메모리 점유율, 디스크 사용률 panel이 No data 상태인 것을 보실 수 있는데요.
각각 가공하는 Data의 종류가 맞지 않아서 그럴 확률이 높습니다.
sum by (instance) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", node="$node"}[5m]))
CPU 점유율 panel의 경우 edit하여 Query를 보면 위처럼 node로 명시되어 있습니다. 하지만 현재 저희는 Amazon EKS를 사용하고 있으니 저 이름은 node가 아니라 instance가 되어야 정상적으로 보여집니다!
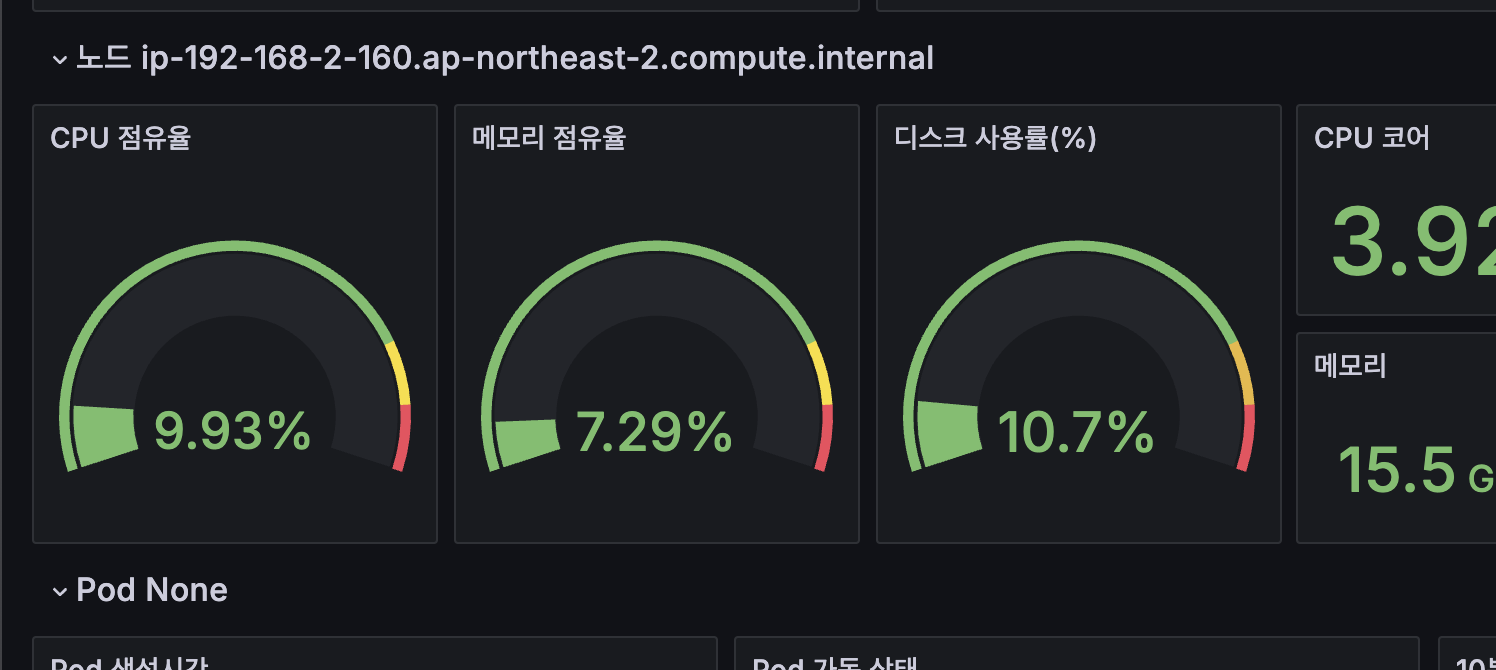
sum by (instance) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", instance="$instance"}[5m]))
이처럼 나머지들도 값을 변경하면 아래와 같이 정상적으로 보여집니다!
Grafana Alert
Grafana를 통해 수집된 metric 데이터을 가공하여 임계값을 만든 후 해당 임계값에 도달하거나 넘게 되면 설정해놓은 contact point로 메시지를 전송할 수 있습니다.
다양한 contact point가 있지만 저는 Slack을 통해 Webhook을 전송받도록 하겠습니다.
Slack App 만들기
먼저 https://api.slack.com/apps/에 접속합니다.
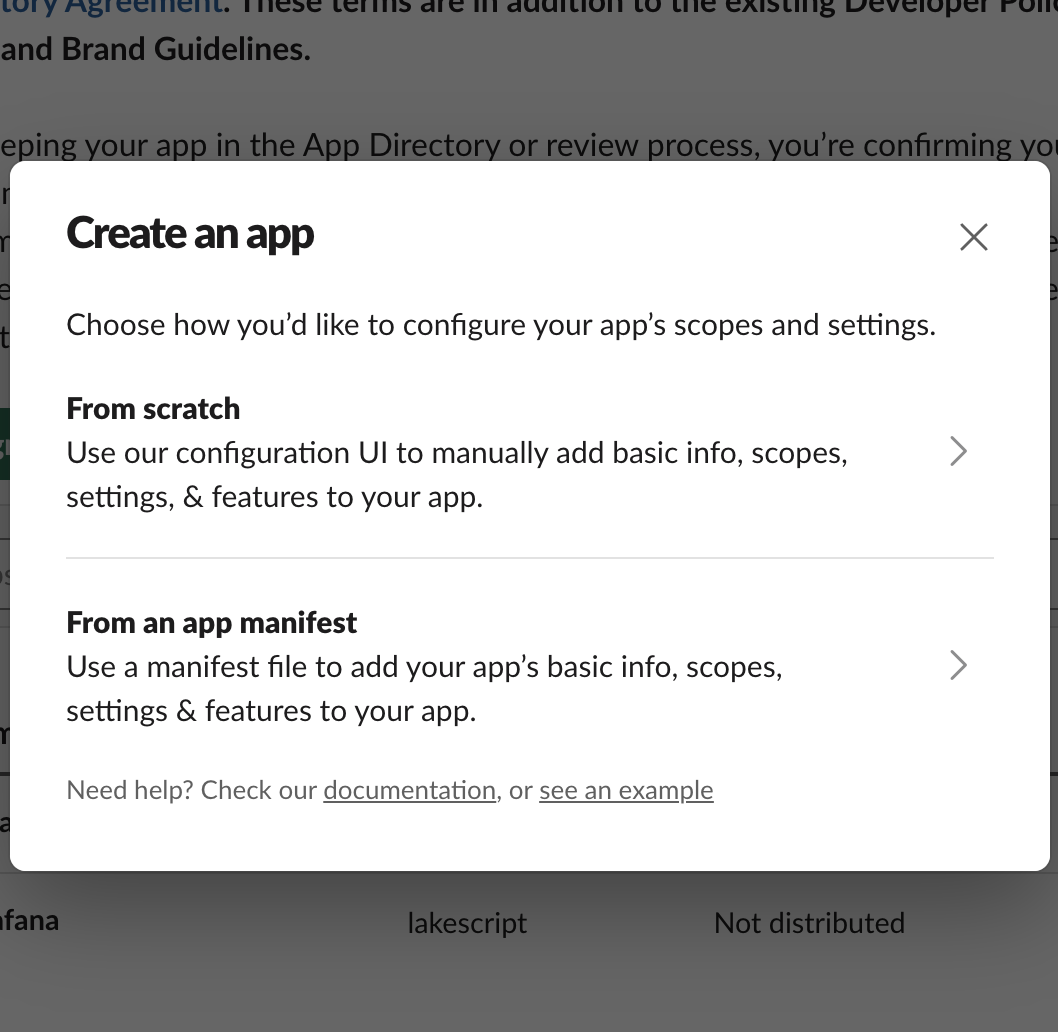
그 후 Create New App 버튼을 클릭한 후 From scratch 에 접근하여 생성할 App의 정보를 입력하고 workspace를 설정합니다.

Incoming Webhooks에 접속하여 해당 기능을 활성화합니다.
그 후 Add New Webhook to Workspace 버튼을 클릭하여 해당 workspace의 채널을 설정합니다.
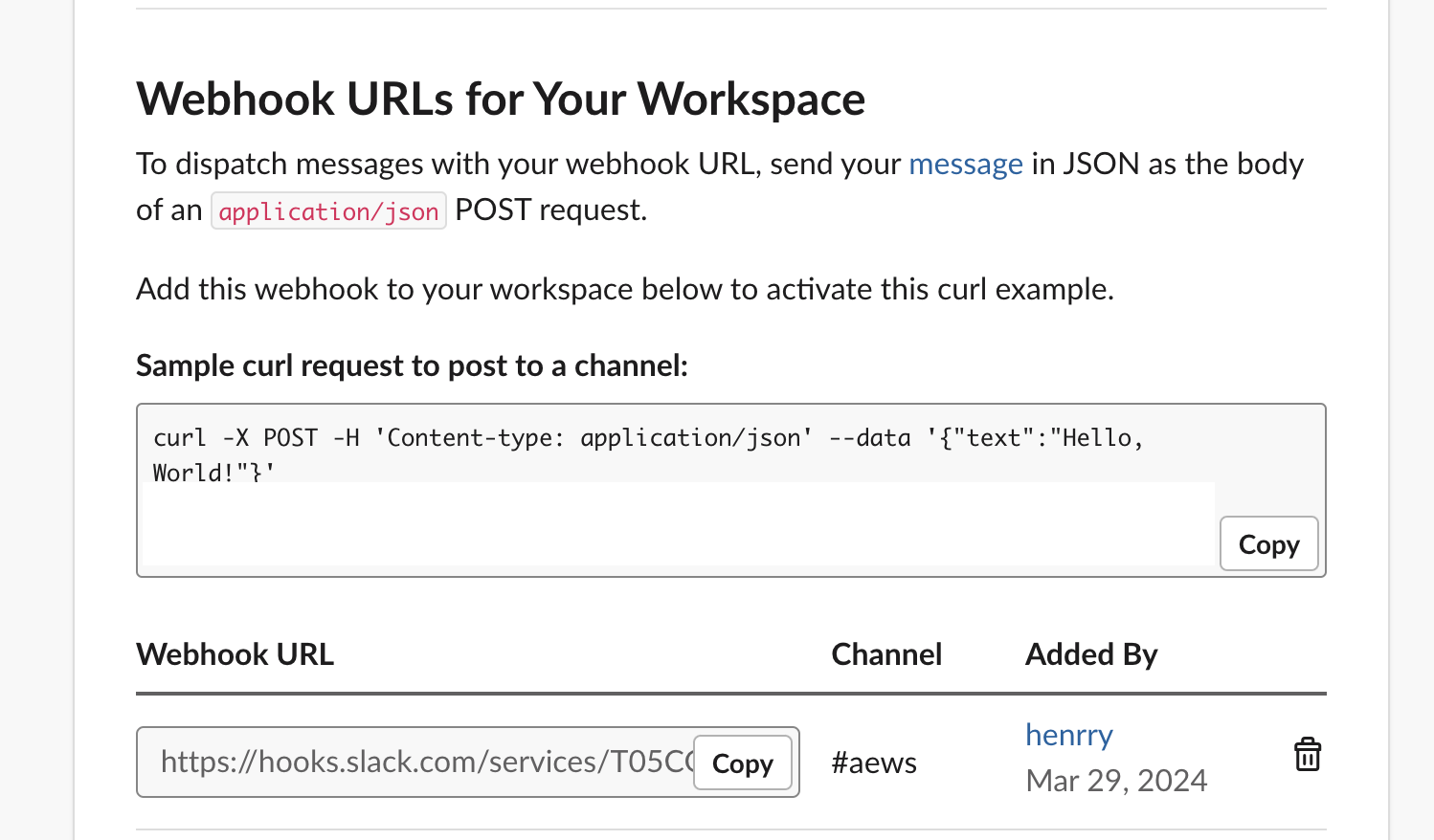
그럼 위의 사진과 같이 Webhook URL이 생성된 것을 확인하실 수 있고 아래와 같이 해당 채널에 추가된 것을 확인하실 수 있습니다.

Grafana Alert Rule 만들기
grafana에서 Alerting 메뉴에 접근하신 뒤 Alert ruels를 클릭합니다. 그 후 New alert rule를 클릭하여nginx 웹 요청 1분 동안 누적 60 이상 시 메시지를 보내는 Alert를 설정합니다.
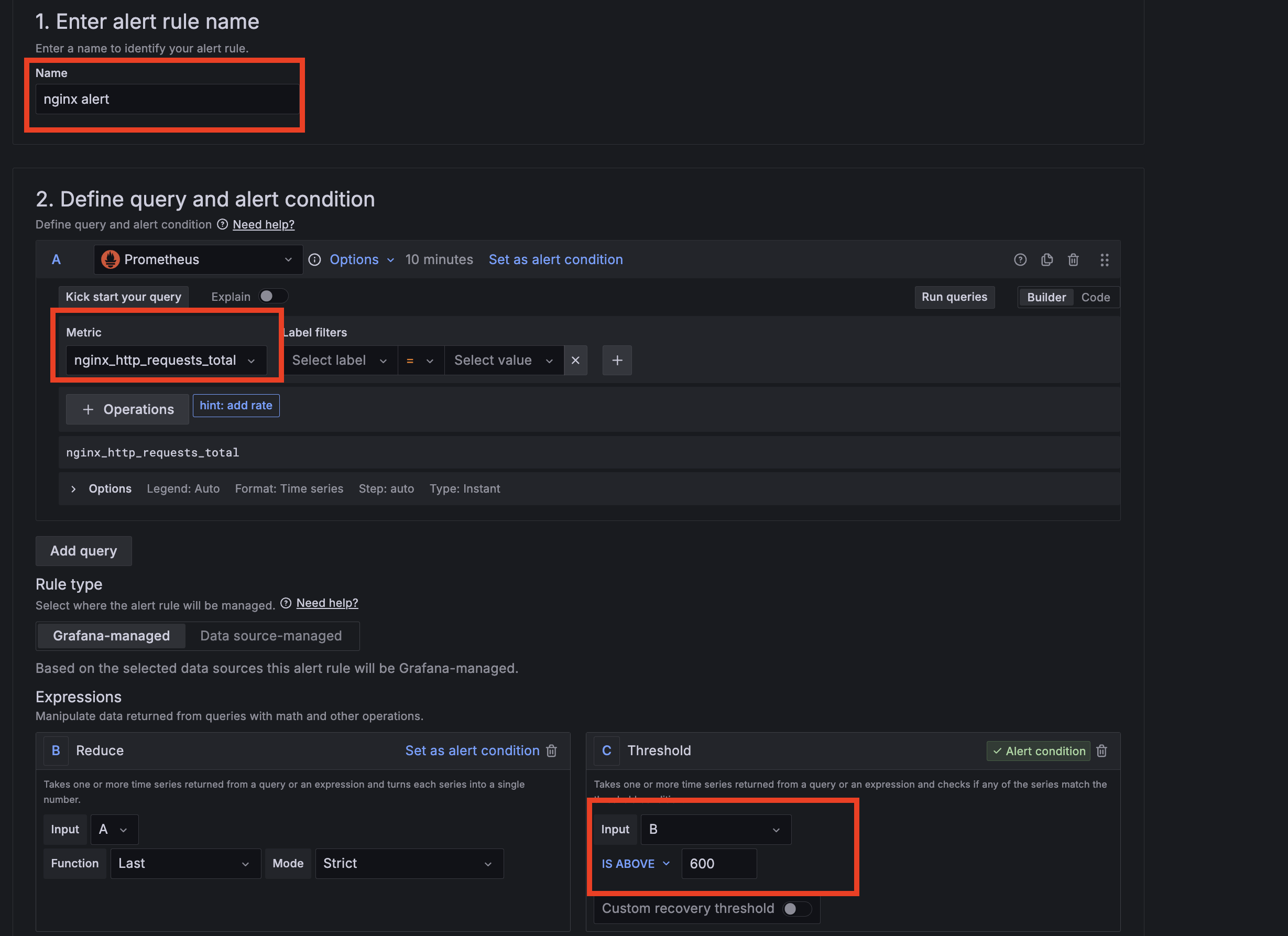
그 후 아래 Folder 과 Evaluation group(1m), Pending period(1m) 은 +Add new 클릭 후 신규로 만들어 줍니다.
알림을 받기 위해 Contact points메뉴에 접근하여 Add contact point 클릭합니다.
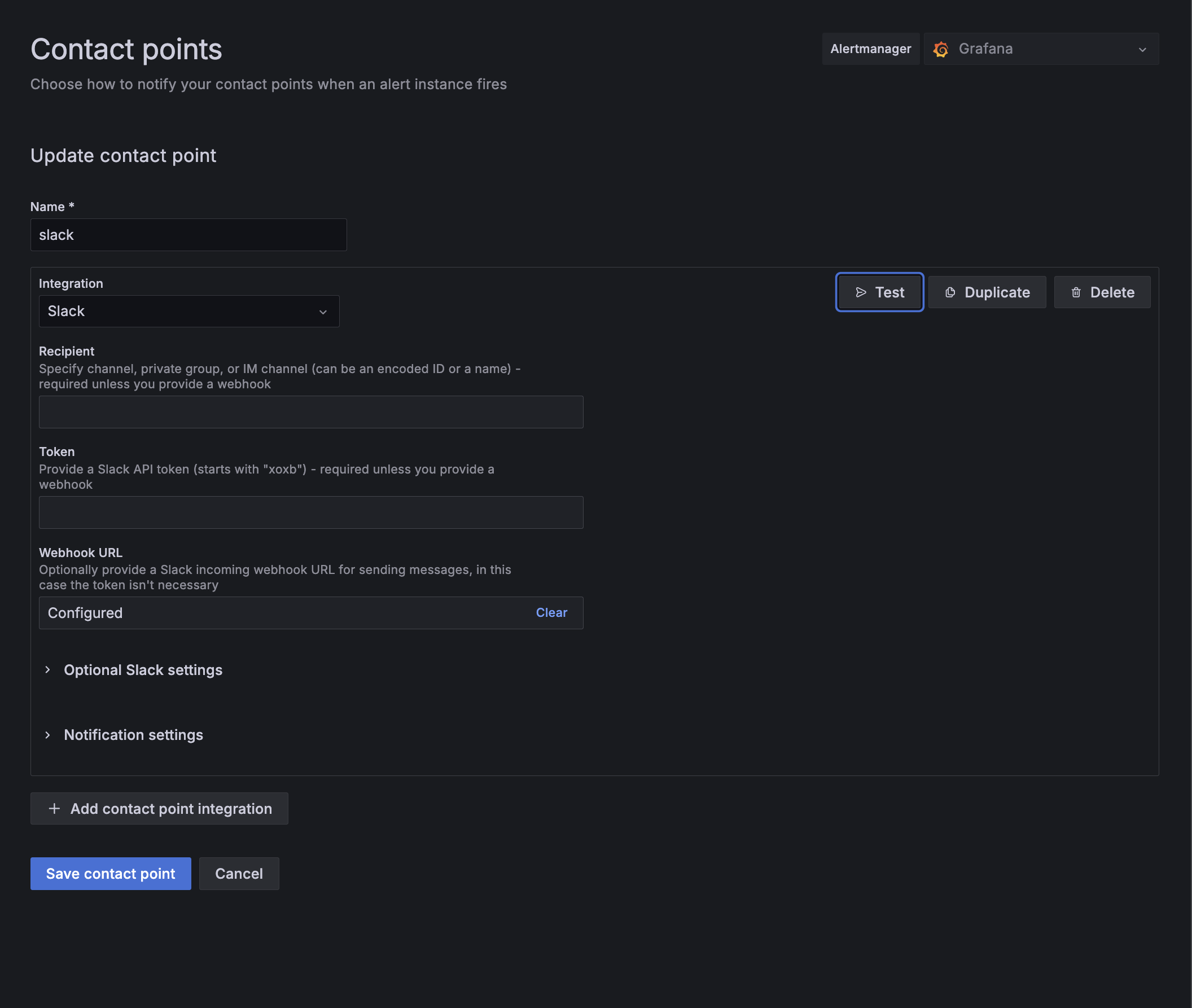
name을 적은 후 Intergraion에 Slack을 찾고, WebhookURL에 위에서 생성한 Slack App의 Incomming Webhook URL을 입력합니다.
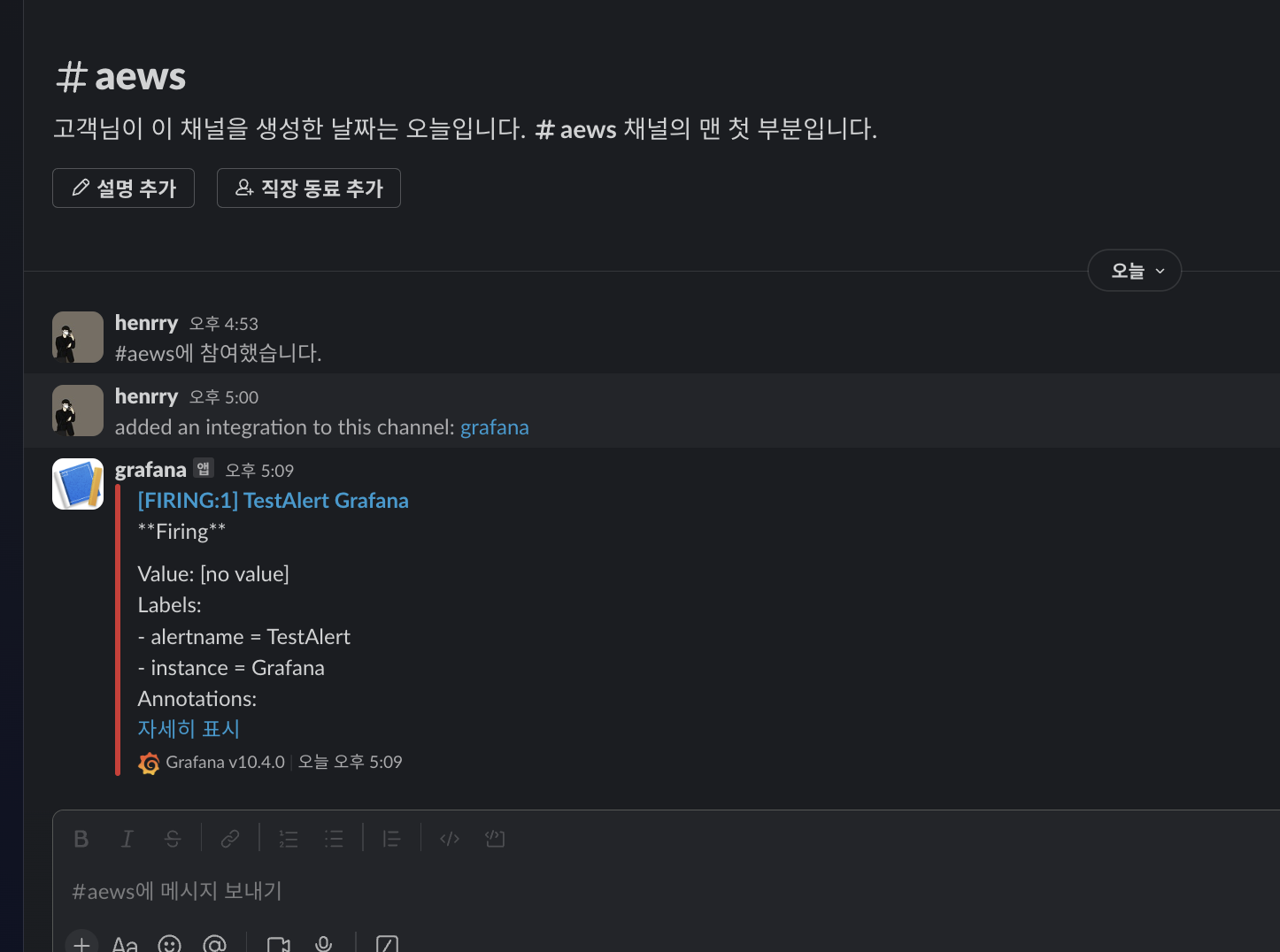
오른쪽 상단에 Test 버튼을 클릭하면 아래와 같이 Slack 채널에 알림이 전송됩니다.
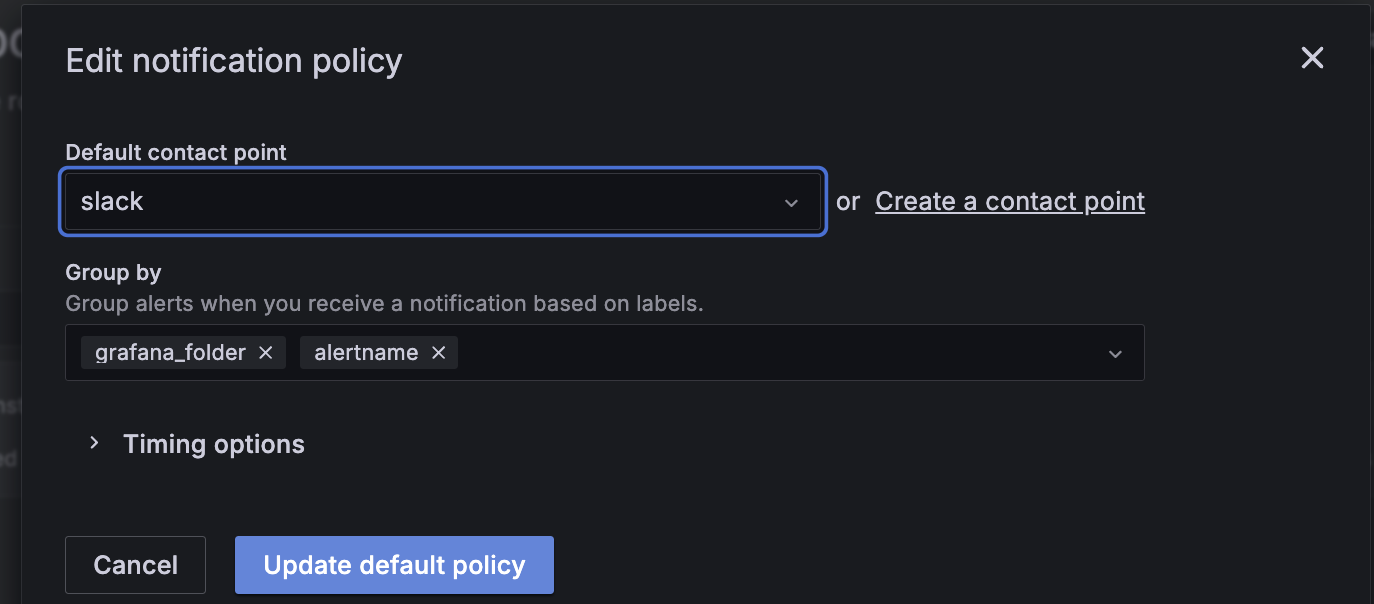
마지막으로 Notification policies 메뉴에 접근하여 default contact point를 email에서 slack으로 수정합니다.
이제, 아래의 명령어로 Nginx pod에 계속 접근해보겠습니다.
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; done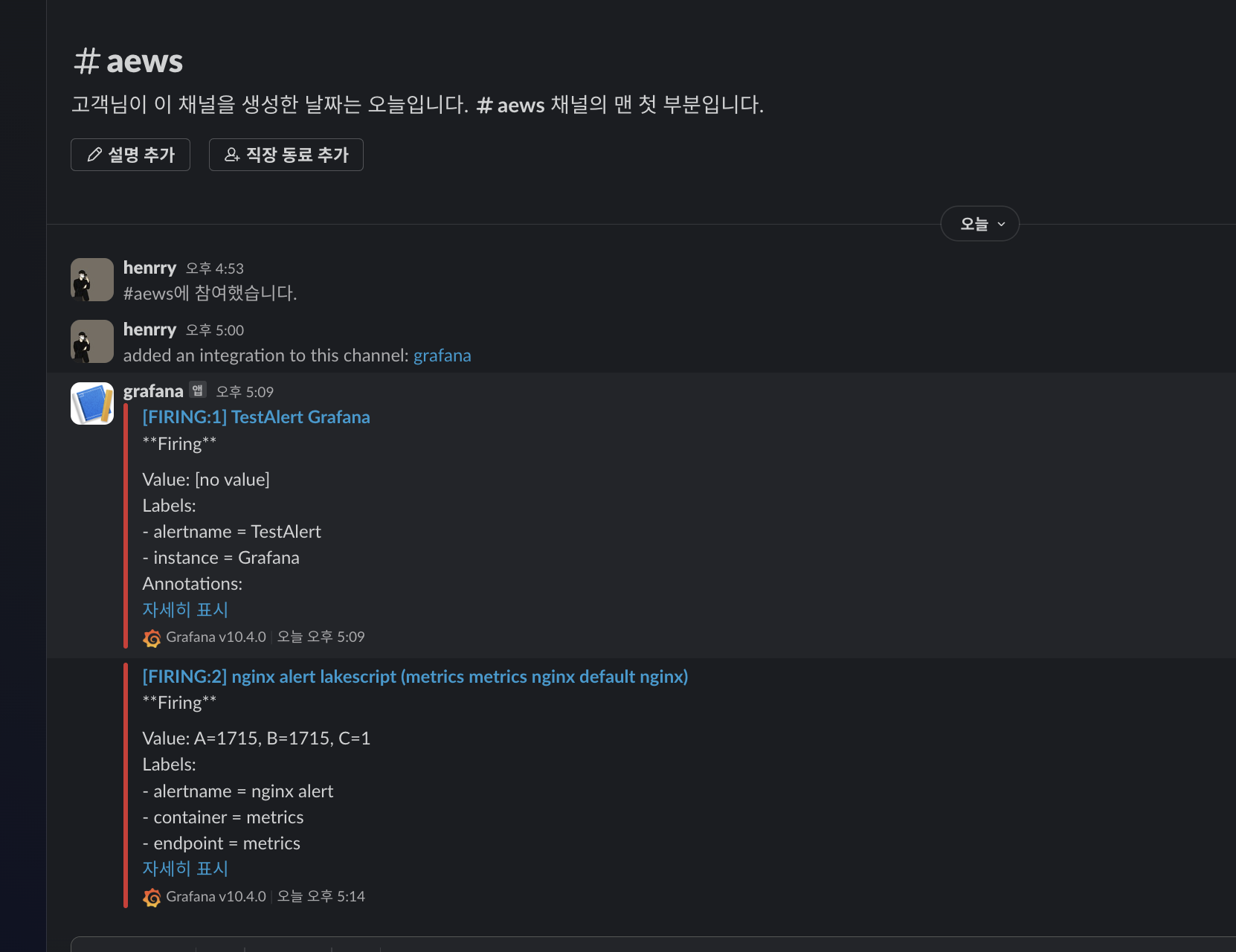
정상적으로 alert 가 수신된 것을 확인하실 수 있습니다.
'스터디 이야기 > 24' AWS EKS' 카테고리의 다른 글
| [AEWS] 5-2. Amazon EKS - Autoscaling (CA, CPA) (0) | 2024.04.02 |
|---|---|
| [AEWS] 5-1. Amazon EKS - Autoscaling (HPA, KEDA, VPA) (0) | 2024.04.01 |
| [AEWS] 4-2. Amazon EKS - Observability (Prometheus) (2) | 2024.03.29 |
| [AEWS] 4-1. Amazon EKS - Observability(EKS Logging) (0) | 2024.03.25 |



