
이 스터디는 CloudNet@에서 진행하는 KANS 스터디를 참여하면서 공부하는 내용을 기록하는 블로그 포스팅입니다.
CloudNet@에서 제공해주는 자료들을 바탕으로 작성되었습니다.
컨테이너 격리
이전 글(pivot_root, namespace)을 통해 컨테이너를 논리적으로 격리하는 방법에 대해 실습을 통해 알아보았습니다. 그렇다면 컨테이너 환경에서 자원에 대한 격리는 어떻게 이루어질까요? 바로 리눅스 커널의 기능 중 cgroup을 통해 자원을 격리합니다.
Cgroup
Cgroup(control group)은 리눅스 커널의 기능으로, 프로세스 그룹에 대한 자원 할당을 관리하고 제어할 수 있는 메커니즘입니다. 즉, 프로세스가 사용하는 CPU, 메모리, 디스크 I/O, 네트워크 대역폭 등의 시스템 자원을 제한하거나 격리할 수 있게 해줍니다. 특히 Cgroup은 컨테이너 기술에서 핵심적인 역할을 하며, 컨테이너가 다른 컨테이너 및 호스트 시스템과 자원을 독립적으로 사용할 수 있도록 합니다.
host 내의 cgroup 확인
tree -L 1 /sys/fs/cgroupcgroup과 관련된 파일 및 디렉터리의 구조를 한 눈에 파악하도록 tree 명령어를 통해 확인해보겠습니다.

각 디렉터리는 해당 자원(예: CPU, 메모리, 블록 I/O 등)의 cgroup 설정과 관련된 파일을 포함하고 있습니다.
Cgroup 기본 실습
관리자 권한 실행
sudo su -
cgroup2 파일 시스템 mount
mount -t cgroup2mount 명령어를 통해 리눅스에서 cgroup2 파일 시스템을 마운트합니다.

findmnt 명령어를 통해 확인
findmnt -a
실습환경인 Ubuntu 22.04는 cgroup이 아닌 cgroup2를 사용하기에 fstype이 cgroup2로 보여집니다.
[터미널 2] sleep 명령어 실행
sleep 100000또 다른 터미널을 열어서 실습 환경에 접근한 뒤 sleep 명령어를 실행합니다.
[터미널 1] /proc에 cgroup 정보 확인
cat /proc/$(pgrep sleep)/cgroupcgroup을 파일시스템으로 격리한 터미널1에서 위의 명령어를 통해 sleep 명령어를 실행한 쉘의 cgroup을 확인해보겠습니다.

tree /proc/$(pgrep sleep) -L 2tree 명령어를 통해 하위 디렉토리와 파일까지 살펴보겠습니다.

(중략)

즉, sleep을 실행한 process인 2715의 정보값들을 확인할 수 있는데 그중 ns에 cgroup을 확인하실 수 있습니다.
Cgroup을 통한 자원 격리 실습
cgroup을 이용하여 cpu 자원에 대한 격리를 실습해보겠습니다.
자원 확인 tool 설치
apt install cgroup-tools stress -y원활한 확인을 위하여 stress라는 부하를 주입할 수 있는 tool을 설치합니다.
[터미널2] htop 명령어 실행
htop새로운 터미널에서 실습환경에 접속한 뒤 시스템의 프로세스 및 리소스 사용 상태를 실시간으로 모니터링할 수 있도록 시각적으로 제공하는 터미널 기반 프로그램인 htop을 실행합니다.
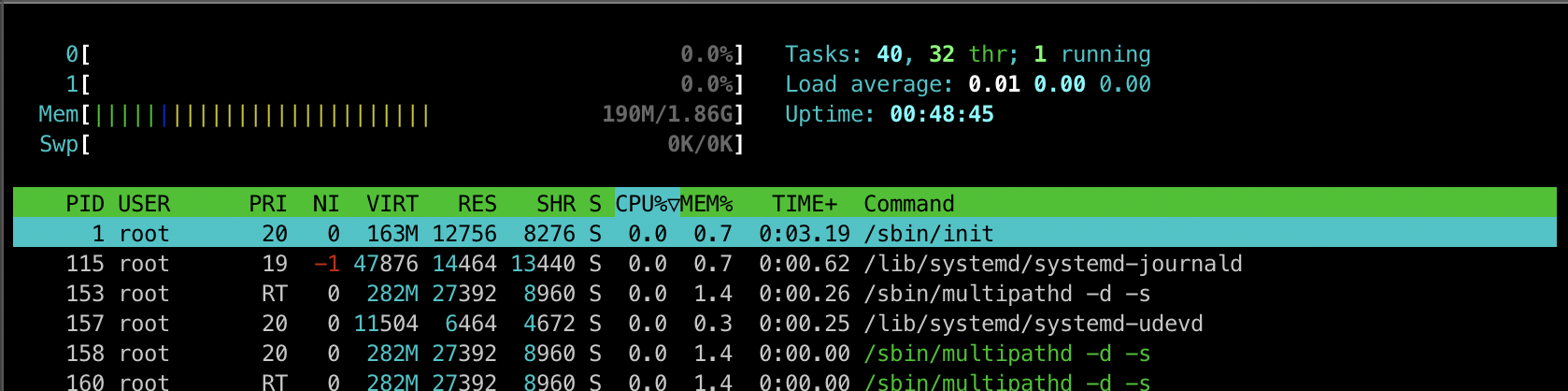
현재 2개의 CPU가 존재합니다.
[터미널1] stress 명령어를 통해 cpu 부하 주입
stress -c 1stress 명령어에 -c 옵션을 주어 CPU에 1개의 작업 스레드를 만들어서 CPU를 최대한 사용할 수 있도록 합니다.

[터미널2] CPU 확인
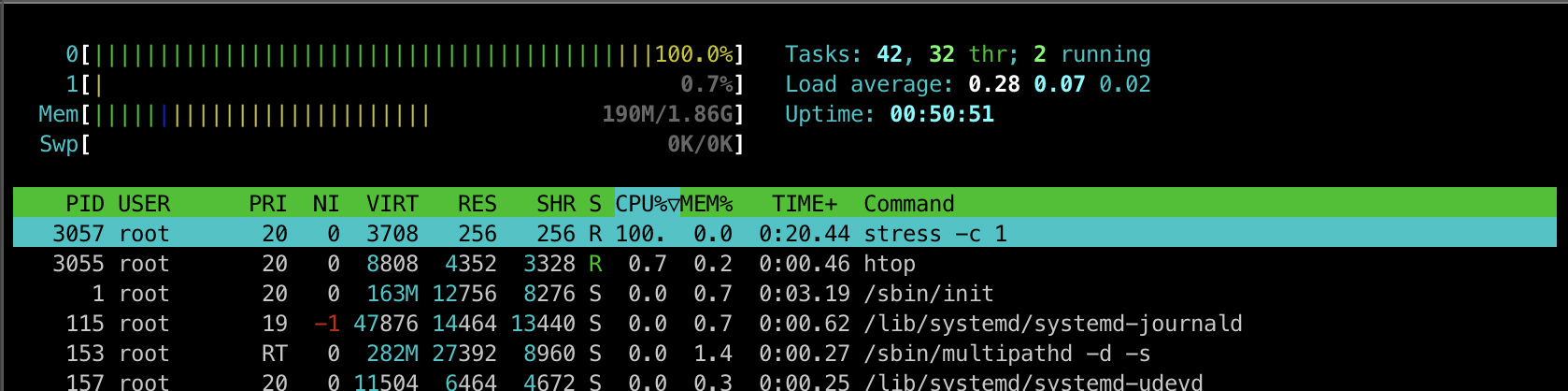
3057 PID의 프로세스가 CPU를 100% 사용하는 것을 확인하실 수 있습니다.,
[터미널1] 디렉토리 이동 후 격리할 디렉토리 생성
cd /sys/fs/cgroup
mkdir test_cgroup_parent && cd test_cgroup_parentcpu 리소스 격리를 테스트할 부모 디렉토리를 생성합니다.
[터미널1] tree 명령어를 통해 파일 및 디렉토리 구조 확인
tree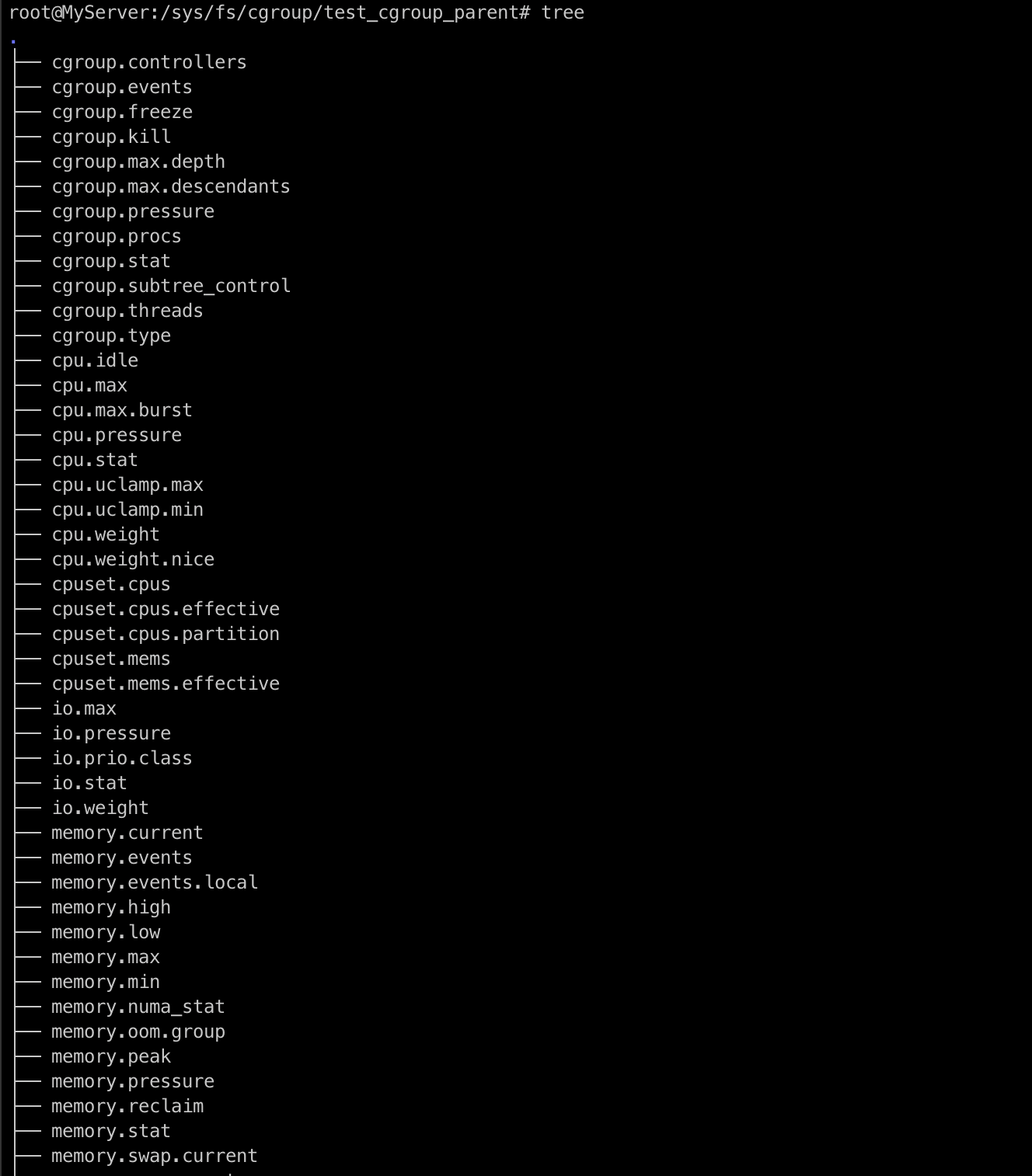
/proc 디렉토리와 유사하게 해당 경로에 디렉토리를 만들면 안에 파일 및 디렉토리가 자동으로 생성됩니다.
[터미널1] 제어 가능한 목록 확인
cat cgroup.controllerscgroup.controllers의 내용을 통해 현재 제어 가능한 리소스 자원 목록을 확인합니다.

[터미널1] subtree_control를 추가하여 컨트롤 할 수 있도록 설정
echo "+cpu" >> /sys/fs/cgroup/test_cgroup_parent/cgroup.subtree_control
[터미널1] cpu.max에 격리/제한할 cpu 값을 입력
echo 100000 1000000 > /sys/fs/cgroup/test_cgroup_parent/cpu.maxcpu.max에 100000/1000000 즉, 1/10만큼의 cpu 리소스를 제한합니다.
[터미널1] 자식 디렉토리 생성
mkdir test_cgroup_child && cd test_cgroup_child해당 경로에 자식 디렉토리를 생성 후 이동해줍니다.
[터미널1] 현재 세션의 프로세스를 cgroup.procs로 이동
echo $$ > /sys/fs/cgroup/test_cgroup_parent/test_cgroup_child/cgroup.procs현재 쉘 세션의 프로세스를 test_cgroup_parent/test_cgroup_child cgroup으로 이동합니다.
이렇게 되면 현재 쉘 프로세스가 해당 cgroup에 속하게 되며, 그 cgroup에 적용된 리소스 제한이나 정책을 따르게 됩니다. 즉, 현재 쉘 프로세스가 위에서 설정한 cpu.max 정책에 따라 CPU를 제한받게 됩니다.
[터미널1] stress 명령어를 통해 CPU 부하 주입
stress -c 1
[터미널2] htop 명령어로 부하 확인
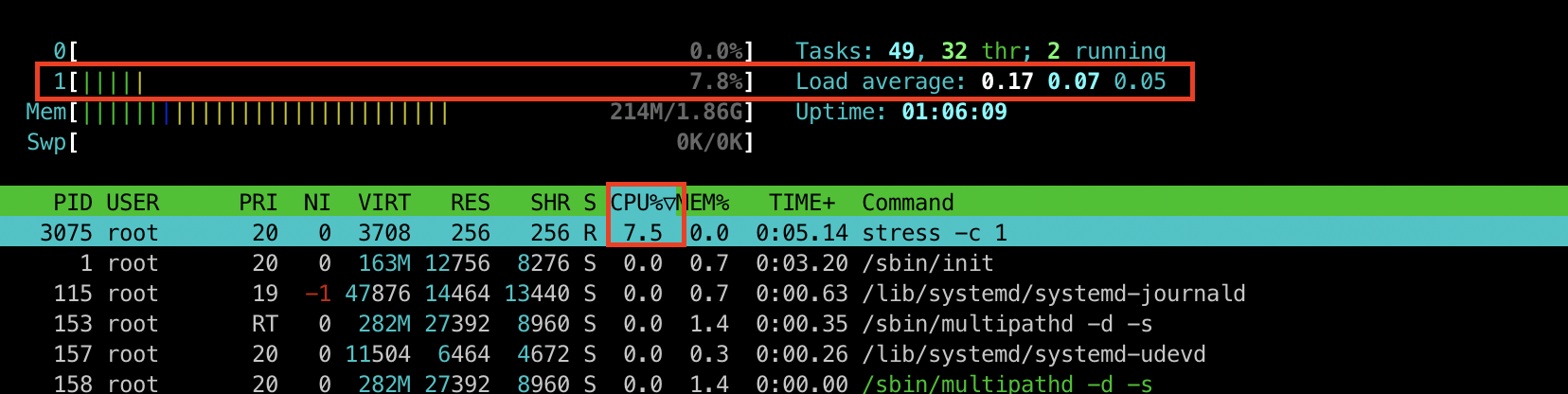
부모 디렉토리에서 cpu.max를 1/10으로 제한한 후 자식 디렉토리에서 cpu 부하를 주입했더니 1/10만큼 부하가 제한되었습니다.
[터미널1] cgroup.subtree_control에 memory 추가
echo "+memory" >> cgroup.subtree_control이번엔 memory에 대한 부하를 주입하기 위해 cgroup.subtree_control에 memory를 추가해줍니다.
[터미널1] cgroup.stress_control 확인
cat cgroup.stress_control
memory에 대한 내용이 추가된 것을 확인하실 수 있습니다.
[터미널2] htop 명령어를 통해 리소스 확인
htop부하를 주입하기 전 리소스 사용량을 확인해보겠습니다.
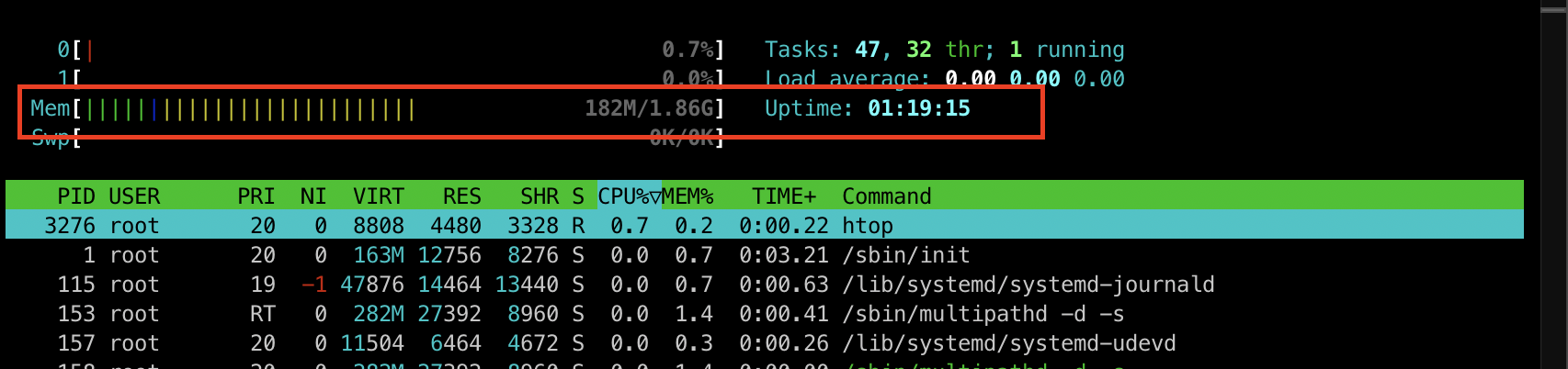
180M 정도 사용하고 있는것을 확인할 수 있습니다.
[터미널1] stress 명령어를 통해 memory 부하 주입
stress -m 1 --vm-bytes 512M --vm-keep
[터미널2] htop 명령어를 통해 리소스 확인
htop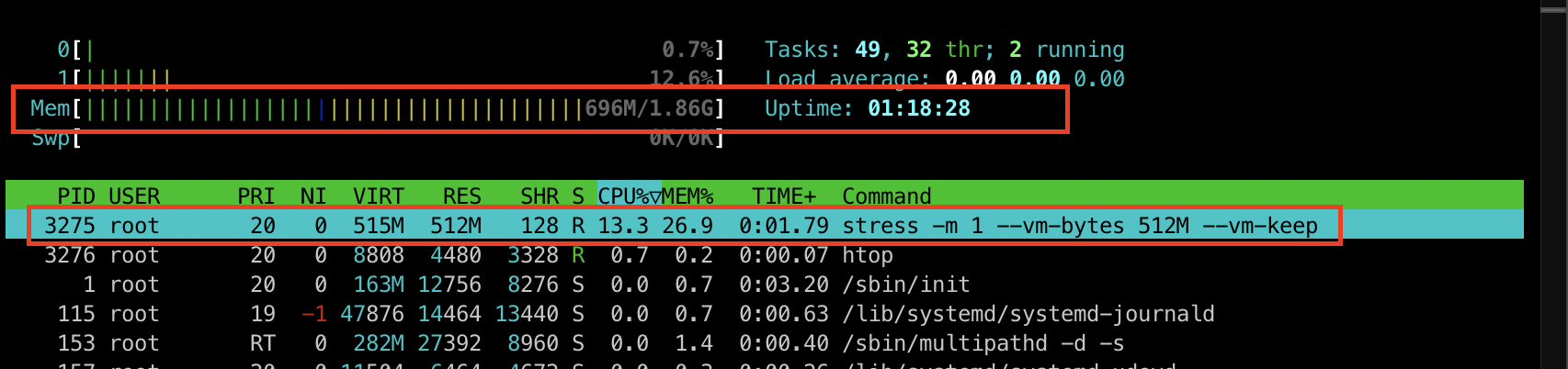
부하를 주입하고 난 후 htop 명령어를 통해 리소스 사용량을 확인해보니 696M 정도 사용하고 있는 것을 확인하실 수 있습니다.
[터미널1] 리소스 격리
echo 104857600 > /sys/fs/cgroup/test_cgroup_parent/memory.max
or
echo 100M > /sys/fs/cgroup/test_cgroup_parent/memory.max메모리를 100M로 제한하기 위해 바이트로 104857600를 memory.max에 넣어줍니다. 혹은 단위를 넣어서 100M으로 넣어주셔도 됩니다.
[터미널1] 자식 디렉토리로 이동 후 stress 명령어를 통한 메모리 부하 주입
cd test_cgroup_child
stress -m 1 --vm-bytes 512M --vm-keep자식 디렉토리로 이동 후 메모리 부하를 주입해보겠습니다.

메모리 부하가 정상적으로 주입되지 않고 해당 프로세스가 종료됩니다. 즉, CPU와 다르게 Memory는 memory.max에서 설정한 메모리 제한을 넘어가는 요청이 오게되면 메모리 할당을 처리하지 못했기 때문에 커널이 프로세스를 강제로 종료하여 메모리 초과를 방지합니다. 이처럼 K8s에서도 Pod에 할당된 Memory 보다 큰 요청이 오게 되면 OOM이 발생하게 됩니다.
'스터디 이야기 > Kubernetes Advanced Networking Study' 카테고리의 다른 글
| [KANS] Pod - pause container (4) | 2024.09.05 |
|---|---|
| [KANS] Docker In Docker - Kind (0) | 2024.09.05 |
| [KANS] 컨테이너 격리 - 2. namespace (1) | 2024.08.29 |
| [KANS] 컨테이너 격리 - 1. chroot, pivot_root, mount namespace (2) | 2024.08.29 |



